
Notice
Recent Posts
Recent Comments
Link
반응형
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- aws #아키텍트 #과정 #vpc #인프라 구축 #amazon sns #server #less #architecture
- aws #아키텍트 #과정 #vpc #인프라 구축 #rds #endpoint #cloudwatch #monitoring
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- 썸네일 #이미지
- 공간복잡도 #공간자원 #캐시메모리 #SRAM #DRAM #시간복잡도
- aws #아키텍트 #과정 #vpc #인프라 구축 #t.g #target group #alb #application #load #balancer #web #server
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- aws #아키텍트 #과정 #vpc #인프라 구축 #php #alb #application #load #balancer #security #group #igw #ec2 #vpc #virtual #private #cloud
- aws #아키텍트 #과정 #vpc #인프라 구축 #s3 #bucket #객체 #스토리지 #isci #이미지 #업로드
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #OSI #ISO #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- aws #아키텍트 #과정 #vpc #인프라 구축 #auto scailling #lauch template #ec2 instace #private #subnet
- aws #아키텍트 #과정 #vpc #인프라 구축 #haproxy #round robin #process #high ability #auto scailling #app server #launch template
- 쓰레드 #쓰레드풀 #프로세스
- aws #아키텍트 #과정 #vpc #인프라 구축 #ec2 #instance #launch #template #생성 #ami #amazone #machine #image
- aws #아키텍트 #과정 #vpc #인프라 구축 #db #장애조치 #reand only #replica #events
- 프로세스 #CPU #시공유 #커널
- aws #아키텍트 #과정 #vpc #인프라 구축 #rds #replica #복제본 #aurora #database #고가용성
- 비트 #바이트 #이진수
- aws #아키텍트 #과정 #vpc #인프라 구축 #haproxy #고가용성 #테스트 #alb #application #load balancer #application
- aws #아키텍트 #과정 #vpc #인프라 구축 #alb #load balancer #t.g #target #group #haproxy #high ability #db #replica #region
- aws #아키텍트 #과정 #vpc #인프라 구축 #s3 #bucket #객체 스토리지 #objects storage #events #upload #알림
- aws #아키텍트 #과정 #vpc #인프라 구축 #aurora #database #rds #rdbs #load #balancer #web #page #haproxy
- aws #아키텍트 #과정 #vpc #인프라 구축 #second nat #gateway #routing table #route53 #고가용성 #private subnet #
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #웹개발
- 업로드 #lambda #함수 #모바일 이미지 #썸네일 이미지
- aws #아키텍트 #과정 #vpc #인프라 구축 #sqs #trigger #python3.9 #패키지 #
- aws #아키텍트 #과정 #vpc #인프라 구축
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #KDT #기본문법 #데이터베이스 #Computer #Science #CPU #메모리
- aws #아키텍트 #과정 #vpc #인프라 구축 #sqs #message #queue #sns구독
Archives
- Today
- Total
요리사에서 개발자
스파르타 코딩클럽(부트캠프) 2장CPU 와 메모리 심화 본문
반응형
스케쥴링
CS 핵심 용어
프로그램을 실행하는 주체 = 프로세스
작업을 처리해주는 주체 = 쓰레드
CPU를 잘 사용하기 위해서는 프로세스를 잘 배정해야한다.
- CPU는 한정된 자원으로 최대한 성능을 이끌어내기 위해서는 CPU를 적절하고 효율적으로 사용해야 한다.
- OS는 실행 대기중인 프로그램(프로세스)들에게 CPU 자원 배정을 적절히 하여 시스템의 성능을 상승시킬수 있다.
공통 배정조건 : 오버헤드 ↓ / 사용률 ↑ / 기아 현상 ↓
- 오버헤드 : 프로세스가 필요한 자원보다 더 많이 사치부리며 사용하지 않도록
- 사용률: 프로세스가 최대한 자원을 많이 받고 빨리 처리하도록
- 기하현상: 프로세스가 자원할당을 못받아서 대기하지 않도록
목표에 따른 배정조건 3가지
- 배치 시스템 : 가능하면 많은 일을 수행, 시간(Time)보단 처리량(througout)이 중요하다.
- 대화형 시스템 : 빠른 응답 시간, 적은 대기 시간이 중요하다.
- 실시간 시스템 : 실시간(time) 즉 ,최소 응답시간 (dead line) 이 중요하다.
정책에 따라 3가지로 나뉘는 조건.
- CPU이용률 최대화
- 오버헤드 최소화
- 모든 프로세스가 공평하게 분배하는 방식
스케쥴링 단위
CPU, I/O Burst Cycle

프로세스 실행은 “CPU실행 ↔ 입/출력 대기”의 반복을 의미
CPU Burst
프로세스의 사용중 연속적으로 CPU를 사용하는 구간을 의미
실제 CPU를 사용하는 스케쥴링의 단위
I/O Burst
프로세스의 실행 중 I/O 작업이 끝날때까지 Block 되는 구간을 의미
스케쥴링 알고리즘 평가기준
- CPU이용률 : 전체 시스템 시간 중, CPU가 작업을 처리하는 시간의 비율
- 처리량 : CPU가 단위 시간당 처리하는 프로세스의 개수
- 총 처리 시간 : 프로세스가 시작해서 끝날 때 까지 걸린 시간
- 대기시간 : 프로세스가 준비완류 큐에서 대기하는 시간의 총 합
- 응답시간 : 대화식 시스템에서 요청 후 첫 응답이 오기 까지 걸린시간
스케쥴링의 종류
선점 스케쥴링 (Preemptive Scheduling)
OS가 CPU의 사용권을 선점할 수 있는 경우, 강제 회수하는 경우
(처리시간 예측 어려움)
OS가 나서서 CPU사용권을 선점하고 특정 요건에 따라 각 프로세스의 요청이 있을 때 프로세스에게 분배하는 방식
- 가장 자원이 필요한 프로세스에게 CPU를 분배하며 상황에 따라 강제로 회수 할 수 있다.
- 따라서 빠른 응답시간을 요하는 대화식 시분할 시스템에 적합하며 긴급한 프로세스를 제어할 수 있다.
우선순위 스케쥴링(Priority Scheduiling(우선순위 스케쥴링)
- 정적/동적으로 우선순위를 부여하며 우선순위가 높은 순서대로 처리
- 우선순위가 낮은 프로세스가 무한정 기다리는 기아 현상 발생이 가능하다.
- Aging방법으로 기아현상 문제 해결이 가능하다.
미리 주어진 프로세스의 우선순위에 따라서 스케쥴링하는 방식이다.
- 기아(Starvation) : 우선순위가 낮은 프로세스는 할당되지 않기도 하는것
- 노화(Aging) : 기아의 해결볍으로 기다리는 시간에 따라 우선순위를 증가시켜주는 방식.
라운드 로빈(Round Robin)
FCFS에 의해 프로세스들이 보내지면 각 프로세는 동일한 시간의 Time Quantum만큼 CPU를 할당
정해진 시간 할당량 만큼 프로세스를 할당한 뒤, 작업이 끝난 프로세스는 준비완료 큐 의 가장 마지막 큐 에 가서 재할당을 기다리는 방법이다. (회전식)
다단계 큐(Mulilevel-Quene)
준비완료 큐 를 여러개로 분류하여 각 큐가 각각 다른 스케쥴링 알고리즘을 가지는 방식으로 메모리 크기, 우선순위, 유형 등 프로세스의 특성에 따라 하나의 큐에 영구적으로 할당된다.
큐와 큐사이에도 스케쥴링이 필요하며 우선순위 방식, 시분할 방식으로 한다
EX)
우선순위가 높은 Forground Queue
- 대화형 프로세스를 위한 큐
- Round Robin
우선순위가 낮은 Background Queue
- 연산작업을 처리하는 프로세스 큐
- FCFS
Forground 큐가 비어있지 않는 한 Background 큐는 먼저 실행될 수 없으며, Background큐가 먼저 실행중이더라도 Forground큐에 프로세스가 들어오면 선점이 된다.
비선점 스케쥴링(Non-prreemptive Scheduling)
프로세스 종료 or I/O등 이벤트가 있을 때까지 실행 보장
(처리시간 예측 용이)
어떤 프로세스가 CPU를 할당받으면 그 프로세스가 종료되거나, 입 출력 요구가 발생하여 자발적으로 중지 될 때 까지 계속 실행되도록 보장하는 방법
- 순서대로 처리되는 공정성이 있고, 다음에 처리해야할 프로세스와 상관없이 응답시간을 예상 할 수있다.
- 선점방식보다 스케쥴러 호출 빈도가 낮고, 문맥교환에 의한 오버헤드가 적다.
- 일괄처리 시스템에 적합하며 자칫 CPU사용시간이 긴 프로세스가 다른 프로세스들을 대기시킬 수 있으므로 처리율이 떨어질 수 있다.
FCFS(First Come, First Serve)
먼저 도착한 프로세스를 먼저 처리하는 기본적인 스케쥴링 알고리즘
특징
큐에 도착한 순서대로 CPU를 할당
실행시간이 짧은 것이 뒤로 가면 평균 대기시간이 길어진다.
비 선점형이며 FIFO큐(먼저 입력된것 먼저 출력)를 이용하여 간단하게 구현한다.
단점
사용중 Convoy Effect(호위효과) 가 발생하는데, 긴 처리시간의 프로세스가 선점되어버리면 나머지 프로세스들은 끝날 때 까지 대기해야한다.
먼저 도착한 프로세스의 버스트 타임에 따라 평균 대기시간 편차가 크다.
SJF(Shorted Job First)
CPU 버스트 타임이 가장 짧은, 최단작업을 우선 스케쥴링 하는 알고리즘
특징
수행시간이 가장 짧다고 판단되는 작업 먼저 수행
FCFS 보다 평균 대기 시간감소, 짧은작업의 유리하다.
- 가장 적은 평균 대기 시간을 달성할 수 있다.
- CPU 버스트 시간이 동일할 경우 FCFS 방식을 따른다.
- 비선점형일 경우 최소잔여시간 우선 법칙을 따른다.
HRN(Hightest Response - radio Nest)
특징
우선순위를 계산하여 점유 불평등 보완(SJF 단점 보완)
우선순위 = (대기시간 + 실행시간) / (실행시간)
스케쥴링 동작시점
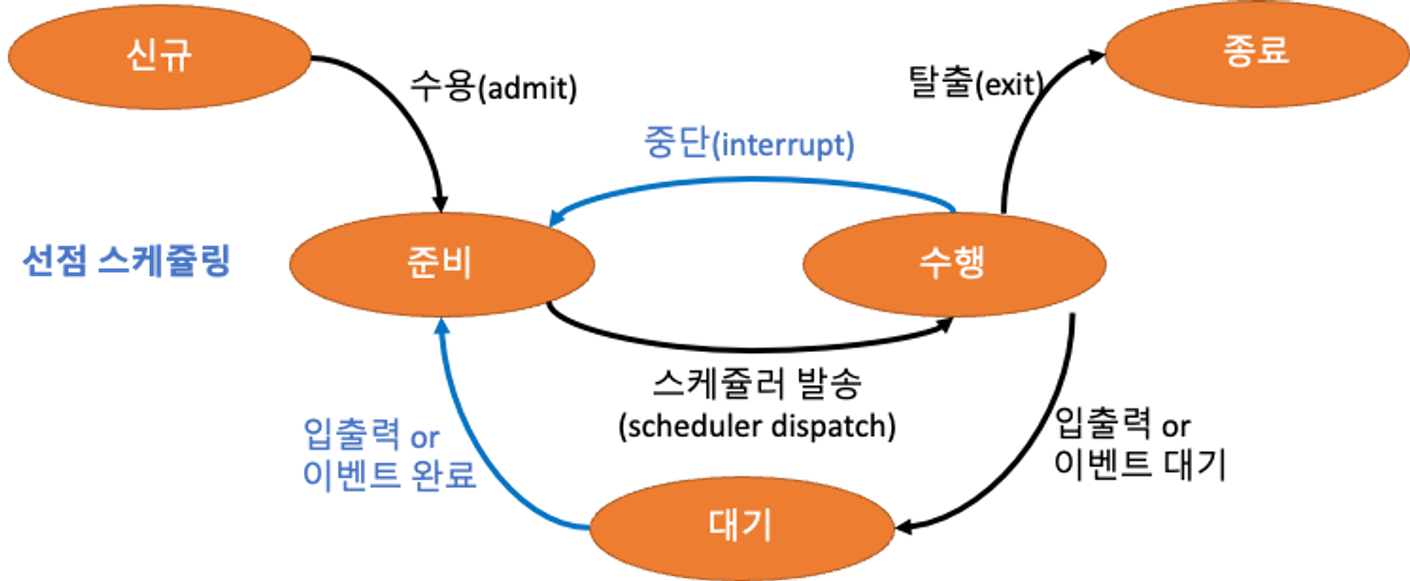
프로세스의 상태변화와 스케쥴링
스케쥴링 알고리즘에 따라 프로세스들은 상태변화가 알어나며 준비/수행 상태일 때 CPU를 사용한다.
아래그림에서
- 🟠은 프로세스들의 상태를 의미하고
- 🔜 은 스케쥴링에 따라 상태가 변화되는 동작을 의미합니다.

- 수행 -> 대기 (Running->Waiting) : I/O요청이 발생하거나, 자식 프로세스가 종료 대기를 할 때
- 수행 -> 종료 (Running -> Terminate) : 프로세스를 종료시켯을때
- 수행 -> 준비 (Running-> Ready) : 인터럽트가 발생했을때
- 대기 -> 준비 (Waiting -> Ready) : I/O가 완료되었을때
여기서 1,2은 프로세스가 스스로 CPU를 반환하기에 비선점 스케쥴링이 발생되고

3,4은 프로세스에서 CPU를 강제로 할당(회수)해야 하므로 선점 스케쥴링 이 발생됩니다
1장 복습
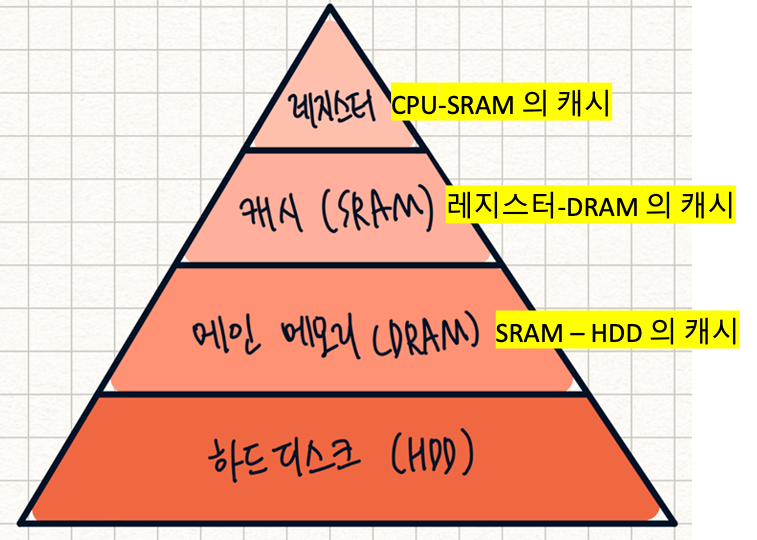
메모리 계층은 레지스터(CPU), 캐시, 메모리, 저장장치로 구성
- 계층 위로 올라갈수록 가격이 비싸지고 용량은 작아지고 속도는 빨라지는 특징을 갖고있다.
- 계층의 존재 이유는 경제성과 캐시 때문이다.
ex) '로딩중' = '하드디스크 또는 인터넷에서 데이터를 읽어 RAM으로 전송하는 과정이 끝나지 않았다'를 의미
레지스터는 연산에 필요한 데이터를 저장하고 빠르속도로 접근할 수 있는 저장공간.
- CPU안에 있는 작은 메모리 이다.
- 휘발성이다.
- 속도가 가장 빠르다.
- 기억용량이 가장 적다.
캐시 메모리는 컴퓨터가 전원이 꺼지면 지워지지만 제일 빠르게 조회 할 수 있는 저장공간.
- L1, L2캐시를 지정
- 휘발성이다.
- 속도가 빠르다
- 기억 용량이 적다
- L3 캐시도 존재한다
L1 : CPU안에 있는 캐시
L2 : CPU 바깥 메모리 영역에 있는 캐시
L3 : L2보다 성능을 더 높이기 위해 메모리영역에 추가된 캐시이다.
주기억장치는 컴퓨터가 전원이 꺼지면 지워지지만 조금 더 빠르게 조회할 수 있는 저장공간.
- RAM을 가리킨다.
- 휘발성이다
- 속도는 보통이다.
- 기억 용량도 보통이다
RAM
하드디스크로부터 일정량의 데이터를 복사해서 임시 저장하고 이를 필요시마다 CPU에 빠르게 전달하는 역할이다.
보조기억장치는 컴퓨터의 전원이 꺼져도 지워지지 않는 저장공간.
- HDD, SDD를 가리킨다.
- 속도는 낮다.
- 기억 용량이 많다.

- 캐시는 데이터를 미리 복사해 놓는 임시 저장소
- 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리
- 데이터 접근에 오래 걸리는 경우를 해결하고 다시 계산하는 시간을 절약한다.
- 캐시는 계층과 계층 사이에서 속도차이를 해결하기 위한 임시 저장소이다.
- ex1) 레지스터 : 메모리와 CPU 사이의 속도 차이를 해결하기 위한 캐시
- ex2) 주기억장치 : 캐시 메모리와 보조기억장치 사이의 속도 차이를 해결하기 위한 캐시
화면에 출력되는 데이터는 메인 메모리에 저장된 데이터.
1. 프로그램이 실행되면 디스크를 읽어서 메인 메모리에 복사
2. CPU(MMU)가 메인 메모리에서 데이터를 읽어오며 작업을 처리.
3. 캐시가 중간에서 한번 더 메인 메모리에 데이터를 복사해두는것.
SRAM(L1,L2,L3캐시) : 정적 메모리로써 용량은 작지만 속도는 매우 빨라서 캐시용 메모리로 쓰인다.
- 레지스터는 CPU의 연산을 위한 저장소
- 메인 메모리는 실제 프로그램 싱행을 위한저장소
- 이 사이에서 임시저장소 역할만 하는것이 SRAM 이다.
"지역성" 이란
자주 사용되는 데이터의 특성
캐시를 직접 설정할 때 자주 사용되는 데이터를 기반으로 설정하는 특성
시간 지역성 : 최근 사용한 데이터에 다시 접근하려는 특성
ex) for문 안에 선언된 i는 반복문 안에서 계속해서 접근이 이루어지는 변수.
최근에 사용했기 때문이 계속 접근해서 +1이 이루어지는
for(let i=0; i<5; i++){
console.log(i) // 0 1 2 3 4
}
공간 지역성 : 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성
ex) 배열 arr이라는 공간에 i가 연속적으로 항당되어 접근하는 방식
(arr 배열 원소에 대한 공간 지역성)
let arr = [];
for(let i=0; i<5; i++){
arr.push(i)
}
// arr = [0,1,2,3,4]
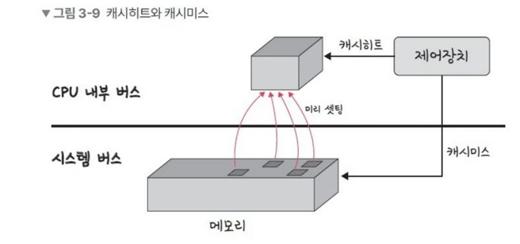
캐시히트와 캐시미스
캐시히트 : 캐시에 원하는 데이터를 찾은것.
- 위치가 가까우며 CPU 내부버스를 기반으로 작동하여 빠르다
- 캐시히트를 하게되면 해당 데이터를 제어장치를 거쳐서 가져오게 된다.
캐시미스란 : 해당 데이터가 캐시에 없다면 주메모리로 가서 데이터를 찾아오는것
- 메모리를 가져올 때 시스템 버스를 기반으로 작동하기 때문에 느리다.
캐시 매핑 : 캐시가 히트되기 위해 매핑되는 방법
CPU의 레지스터 와 주 메모리(RAM)간에 데이터를 주고 받을 때를 기반한다.
주 메모리에 비해 굉장히 작은 레지스터가 캐시계층으로써 역할을한다(매핑이 중요하다)
직접매핑
- 메모리가 1~100이 있고 캐시가 1~10이 있다면 1:1~10, 2:1~20..와 같이 매핑한다.
- 처리가 빠르지만 충돌 발생이 잦다
연관 매핑
- 순서를 일치하지않고 관련 있는 캐시와 메모리를 매핑
- 충돌이 적지만 모든 블록을 탐색하기에 속도가 느리다
집한 연관 매핑
- 직접 매핑과 연관 매핑을 합쳐놓은 것이다
- 순서는 일치하지만 집합을 둬서 저장하기에 블록화가 되어 있어서 검색이 효율적이다.
메모리 할당
메모리에 프로그램을 할당을 할 때에는 시작 메모리 위치와 메모리의 할당크기를 기반으로 할당한다.
연속할당 : 메모리에 연속적으로 공간을 할당하는것
고정 분할 방식과 가변 분할 방식 2가지로 나뉜다.
고정 분할 방식 : 메모리를 미리 나누어 관리하는 방식
- 내부단편화가 발생한다.
가변 분할 방식 : 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용하는 방식
종류
- 최초적합 : 위에서 부터 바로 보이는 공간에 즉시 할당
- 최적적합 : 가장 크기에 맞는 공간부터 채우고 나머지를 할당
- 최악적합 : 가장 크기가 큰 공간부터 채우고 나머지를 할당
외부 단편화가 발생한다 그 이유는 ?
최초적합 (First-fit)
- 메모리 내에서 빈 공간중에 가장 먼저 발견되는 첫 번째 공간에 블록을 할당
- 블록 크기와 공간 크기가 일치하지 않는 경우 남은 공간을 새로운 빈 공간으로 남김
- 초기 메모리 관리를 위한 간단한 방법이지만 외부 조각화가 발생 할 수 있음.
최적적합 (Best-fit)
- 메모리 내에서 블록 크기와 가장 근접한 크기를 가진 가장 작은 빈 공간을 찾아 할당
- 블록 크기와 공간 크기가 일치하지 않을 경우에 남은공간을 새로운 빈 공간으로 남긴다.
- 내부 조각화는 줄일 수 있겠지만 메모리를 탐색하는 데 시간이 걸리므로 성능이 저하 될 수 있다.
최악적합 (Worst -fit)
- 메모리 내에서 가장 큰 빈 공간을 찾아 블록을 할당한다
- 할당된 블록크기와 공간크기가 일치하지 않는경우 외부 조각화가 발생한다.
- 내부 조각화가 적지만 빈 공간을 찾는데 시간이 걸리므로 성능이 저하 될 수 있다.
내부단편화
메모리를 나눈크기보다 프로그램이 작아서 들어가지 못하는 공간이 많이 발생하는 현상
들어갈 수 있는 공간보다 프로그램이 작아 공간이 남는 것을 의미
ex) 나눈 크기는 10씩, 10이라는 메모리 공간에 8크기의 프로그램이 할당되면 2라는 메모리 공간이 남는다
외부단편화
메모리를 나눈 크기보다 프로그램이 커서 들어가지 못하는 공간이 많이 발생하는 현상
들어갈 공간보다 들어갈 것이 더 커서 들어가지 못하고 남아버리는 것.
불연속 할당
- 운영체제에서는 여러 개의 작업을 효율적으로 수행해야하기에 불연속 할당방법을 사용한다.
- 메모리를 동일한 크기의 페이지로 나누고 프로그램마다 페이지 테이블을 두어 이를 통해 메모리에 프로그램을 할당한다
- 1페이징, 세그멘테이션, 페이지드 세그멘테이션 기법이 존재한다
불연속 할당 방식의 단점
메모리 공간 할당과 해제 시 오버헤드가 발생 할 수 있다.(불필요 할당)
메모리 공간이 분산되어 있기 때문에 프로세스가 불연속 공간에 할당될 경우 프로세스의 페이지 교체와 같은 작업이 복잡해질 수 있다.(교체 알고리즘 최적화 필요하다)
운영체제에서 불연속 할당을 사용하는 3가지 방법
1. 링크드 리스트(Linked List)
- 불연속 공간에 프로세스를 할당할 때 할당된 공간의 주소를 연결리스트에 저장하는 방식
- 이 방식은 메모리 할당과 해제가 빠르나, 공간 낭비 발생 할 수 있다.
2. 비트맵(Bitmap)
- 메모리 공간의 각 블록을 0 또는 1로 표시하여 사용 가능한 블록과 사용 중인 블록을 구분하는 방식
- 이 방식은 링크드 리스트보다 효율적인 공간 관리를 제공하나, 메모리 크기가 큰 경우 비트맵이 매우 커지는 단점이 있다.
3. 페이지 테이블(Page Table)
- 가상 메모리 시스템에서 사용되는 방식
- 주소 공간을 페이지라는 작은 블록으로 나누어 사용
- 각 프로세스는 자신의 페이지 테이블을 가지며 페이지 테이블은 무리적인 주소와 가상 주소를 매핑하는 역할을한다
- 이 식은 링크드 리스트와 비트맵보다 효율적으로 가상 메모리를 구현하는 데 필요한 기술이다
페이징
- 동일한 크기의 페이지 단위를 나누어서 메모리간의 서로 다른 위치에 프로세스를 항당한다.
- 빈 데이터(홀)의 크기가 균일하지 않은 문제가 없어지나 주소 변환이 복잡하다
세그멘테이션
- 의미 단위인 세그먼트로 나누는 방식
- 코드와 데이터 등을 기반으로 나눌 수 있으며, 함수 단위로 나눌 수도 있음을 의미한다.
- 공유와 보안 측면에서 좋다.
- 빈데이터(홀) 크기가 균일하지 않는 문제가 발생한다.
페이지드 세그멘테이션
- 공유나 보안은 세그먼트로 나누고 물리적 메모리는 페이지로 나누는 방식이다.
페이지 교체 알고리즘
- 메모리 내에 저장된 페이지 중에 어떤 페이지를 교체할지 결정하는 알고리즘이다
- 페이지 교체 알고리즘은 물리적인 메모리 공간이 한정되어 있을 때 페이지 부재(Page Fault)가 발생하는 상활에서 새로운 페이지를 적재하기 위해 기존 페이지 중 어떤 페이지를 제거할지 결정하는 역할
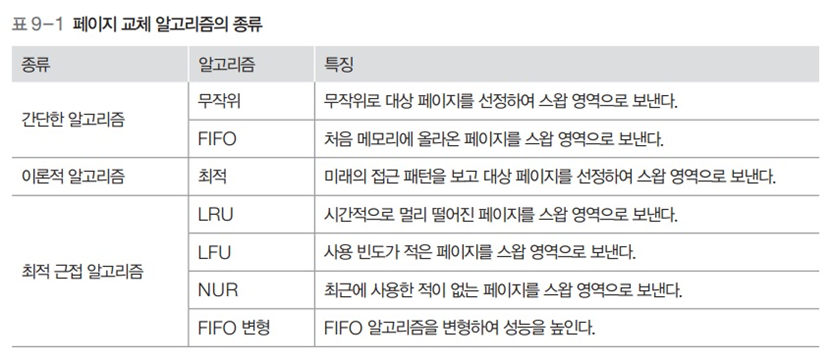
- 여러 알고리즘이 있으며, 각 알고리즘은 다양한 방식으로 페이지를 교체
- 알고리즘에 따라 페이지 부재율(Page Fault Rate) 이나 페이지 교체 오버헤드(Page Replacement Overhead) 등의 성능이 달라진다.
오프라인 알고리즘
- 먼 미래에 참조되는 페이지와 현재 할당하는 페이지를 바꾸는 알고리즘이다
- 입력 데이터가 모두 주어진 상태에서 실행되는 알고리즘이다
- 입력데이터를 모두 가지고 있기 때문에, 실행 중에 입력이 들어오지 않는다.
- 오프라인 알고리즘은 입력데이터를 한꺼번에 처리할 수 있다.
- 실행시간과 공간 사용량을 예측할 수 있다
- 입력데이터의 크기에 따라 적절한 실행 시간과 공간을 예약하여 처리 할 수 있다.
미래에 사용되는 프로세스를 알 수는 없다.
메모리 할당에서는 사용 할 수 없는 알고리즘이나 다른 알고리과의 성능비교에 대한 기준을 제공
오프라인 알고리즘의 대표적인 예 : 정렬 알고리즘
정렬 알고리즘은 입력데이터를 모두 갖고있기에 오프라인 알고리즘이다
입력데이터가 모두 주어졌음으로 한 번에 정렬 할 수 있다
시간기반 알고리즘
1. FIFO(First In FIrst Out)
- 가장 먼저 온 페이지를 교체 영역에 가장 먼저 놓는 방법
- 캐시 메모리에 새로운 데이터가 들어오면 가장 오래전에 들어온 데이터를 제거하고 새로운 데이터를 추가
- 이 방식은 구현이 간단하지만, 오래된 데이터가 최근에 사용된 데이터와 비슷 한 경우 성능이 저하될 수 있다.

2. LRU(Least Recenty Used)
- 참조가 가장 오래된 페이지를 교체하는 방법
- LRU 방식은 가장 최근에 사용된 데이터를 먼저 사용할 가능성이 높기에 캐시 히트(Hit)율을 높일 수 있다.
- 그러나 LRU 알고리즘의 구현 방식은 데이터를 저장하는 데 추가적인 비용이 들어간다.
오래된 것을 파악하기위해 각 페이지마다 계수기, 스택을 두어야 한다는 문제점이 발생한다

3. NUR (Not Used Recently)
- 일명 clock 알고리즘으로 최근 사용여부를 0과 1로 표시하여 교체하는 방법이다
- 1은 최근에 참조
- 0은 참조되지 않음을 의미한다
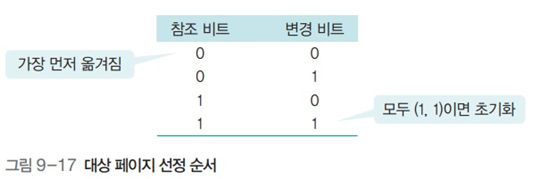
시계 방향으로 돌면서 0을 찾고 0을찾는 순간 해당 프로세스를 교체하여 해당부분을 1로 바꾸는 알고리즘
NUR vs LRU
- LRU : 데이터를 사용 할 떄 마다 최근 사용 시간을 갱신한다.
- NUR : 사용하지 않은 데이터를 주기적으로 스캔하여 최근 사용 여부를 판단한다

빈도기반 알고리즘
LFU(Least Frequently Used)
- 가장 참조 횟수가 적은 페이지를 교체 = 많이 사용하지 않은 것을 교체
- LFU 방식은 사용 빈도가 낮은 데이터를 제거핟여 캐시 히트율을 높일 수 있다.
- LFU 알고리즘은 일부 데이터가 빈번하게 사용되는 경우에 성능저하가 발생할 수 있다.

반응형
'Computer Science' 카테고리의 다른 글
| 스파르타 코딩클럽(부트캠프) 6장 DBMS(데이터베이스 관리 시스템)의 기능과 종류 (2) | 2024.03.22 |
|---|---|
| 스파르타 코딩클럽(부트캠프) 5장 DB(데이터베이스) 구조와 유형 (0) | 2024.03.21 |
| 스파르타 코딩클럽(부트캠프) 4장 프로세스 쓰레드와 쓰레드 (0) | 2024.03.20 |
| 스파르타 코딩클럽(부트캠프) 3장 프로세스 생명주기와 프로세스메모리 (4) | 2024.03.19 |
| 스파르타 코딩클럽(부트캠프) 1장 CPU 와 메모리 (2) | 2024.03.15 |
'Computer Science' Related Articles
more



