
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #KDT #기본문법 #데이터베이스 #Computer #Science #CPU #메모리
- ci/cd파이프라인
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #ci #ioc #의존성
- 프로세스 #CPU #시공유 #커널
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #소셜로그인 #네이버 #기능구현 #vue.js #spring boot #네이버로그인 #연동하기
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #tdd #테스트 주도개발 #테스트코드 #유닛테스트
- 스파르타 코딩클럽 #내배캠 #최종프로젝트 #로그인 #인증인가 #jwt? #토큰인증 #액세스토큰 #리프레시토큰 #쿠키 #파싱 #서명키의 중요성 #security context holder
- 스프링 #백엔드 #자바
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #springmvc패턴 #model #view #controller
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #트랜잭션전파 #transaction
- 비트 #바이트 #이진수
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #대용량트래픽 #처리방법 #캐싱 #코드최적화 #db최적화 #트래픽 #로드밸런서
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #최종프로젝트 #aws s3 #프로필 이미지 수정 #자동삭제
- 스파르타 코딩클럽 #인메모리db #h2 #연동이슈 #문제해결 #방법 #spring security #header #
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- 인가 #
- 쓰레드 #쓰레드풀 #프로세스
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #get방식 #post방식 #http프로토콜 #클라이언트 #백엔드 #api
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #aop #관점지향프로그래밍 #유지보수
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- 보안 #이슈
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #OSI #ISO #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #웹개발
- java5기
- 스파르타 코딩클럽 #내배캠 #최종프로젝트 #4개월삭제 #국비지원 #자바
- 공간복잡도 #공간자원 #캐시메모리 #SRAM #DRAM #시간복잡도
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- 스파르타 코딩클럽 #내배캠 #모의면접 #예상질문 #http 메서드 종류 #메서드 #post #put #get #patch #ci #cd
- 챌린저스 #bod
- spring security #jwt 토큰 #json web token #token #직렬화 #인증
Archives
- Today
- Total
요리사에서 IT개발자로
스파르타 코딩클럽(부트캠프) 7장 자료의 저장과 표현 본문
컴퓨터에서 자료를 저장하고 표현하기 위해 사용되는 주요개념은 비트와 바이트, 파일 시스템, 데이터 형식 등이다.자료는 비트의 형태로 컴퓨터 내부에 저장되며 바이트는 여러개의 비트를 모아놓은 단위이다.
비트와 바이트
컴퓨터 메모리에 저장되는 자료는 0과 1로 이루어진 비트로 표현된다
이진수 체계를 사용하여 자료를 표현, 각 비트는 전기적 신호나 자기적인 방식으로 저장된다.
8개의 비트로 이루어진 바이트는 0과 1의 256가지 조합을 나타낼 수 있다.
이진수 체계
이진수 체계는 0과 1 두가지 숫자만을 사용하여 수를 타내는 수의 체계
이진수는 컴퓨터에서 데이터를 표현, 처리하는 데 중요한 역할을 한다.
이진수 특징
- 이진수는 2진법이라고도 불리며 0과 1을 사용하여 숫자를 표현한다.
- 이진수에서 각 자리는 2의 거듭제곱으로 표현되어 오른쪽에서 왼쪽으로 갈수록 2의 지수가 증가한다.
- 이진수에서 오른쪽부터 왼쪽으로 진행하게되면서 자리마다 2의 지수에 해당하는 값을 할당, 그 값에 0 or 1을 곱하여 해당자리의 값을 구한다.
Ex) 이진수 1010를 10진수로 표현
1 * 2^3 + 0 * 2^2 + 1 * 2^1 + 0 * 2^0
= 8 + 0 + 2 + 0
=10
이진수 장점
- 이진수는 컴퓨터에서 데이터를 표현하는 데 효율적이다.
- 컴퓨터 시스템의 메모리와 프로세서는 0 과 1의 상태를 쉽게 표현하고 처리할 수 있고 이진수를 사용하여 데이터를 저장, 연산을 수행한다
- 비트, 바이트와 같이 작은 단위로 데이터를 표현할 수 있고 데이터의 크기를 효율적으로 관리 할 수 있다.
이진수는 논리연산에도 널리 사용된다.
논리게이트는 이진수의 입력과 출력을 기반으로 논리적인 연산을 수행하며 이진수는 논리연산의 진리값을 표현하는데 사용한다.
이진수로 표현한 10진수 숫자
- 7 : 이진수로 111
- 15 : 이진수로 1111
- 42 : 이진수로 101010.
- 255 : 이진수로 11111111
비트의 개념
비트는 컴퓨터에서 정보를 표현하는 가장 기본적인 단위
비트는 "Binary Digit" 의 줄임말, 이진수 체계에서 0과 1 두가지 값을 가질 수 있는 최소한의 단위
- 컴퓨터 메모리에서는 전기 신호나 자기적인 방식으로 비트를 표현한다.
- 전기신호에서 0 은 낮은 전압, 1은 높은 전압을 나타낸다
- 자기적인 방식에서는 0은 자기적인 극성을 나타내지 않고, 1은 극성을 나타낸다

비트는 두 가지 상태를 가질 수 있으므로 단순한 정보 단위로 보일 수 있으나 여러 비트를 조합하여 복잡한 정보를 나타낼 수 있다.
예를 들어 8개의 비트로 이루어진 바이트는 256(2의 8승) 가지의 조합을 나타낼 수 있다.

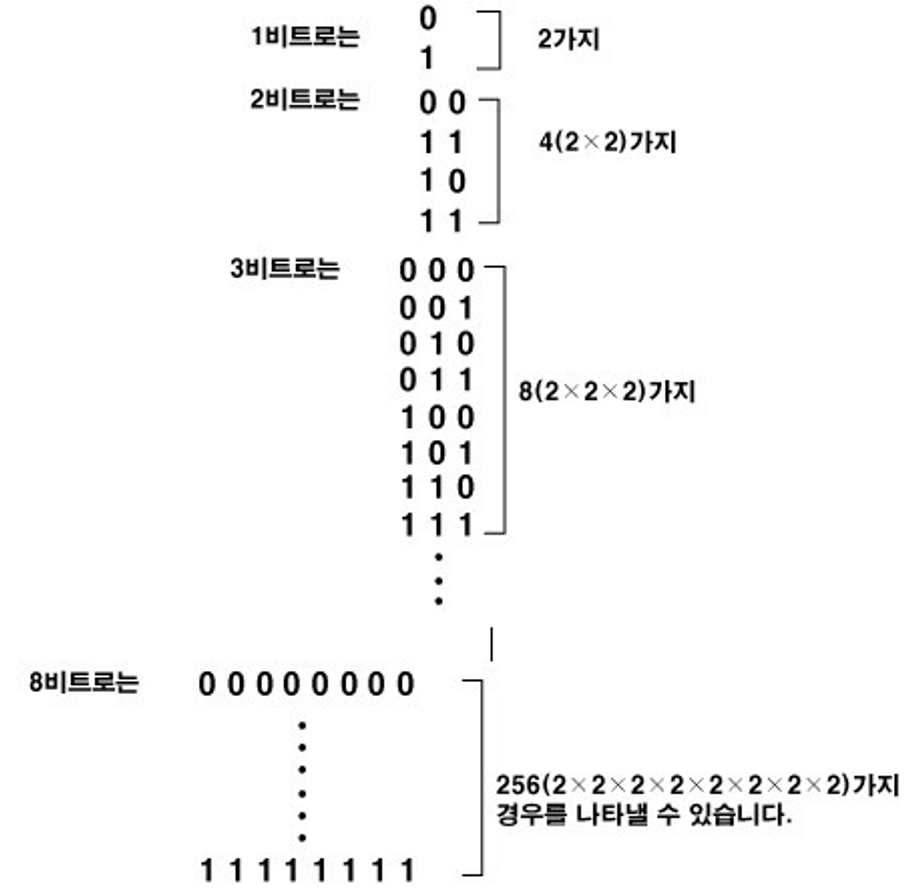
- 비트는 컴퓨터의 모든 데이터를 표현하는데 사용된다.
- 텍스트, 숫자, 이미지, 음악, 비디오 등 모든 종류의 정보는 비트로 변환되어 저장되고 처리된다.
- 컴퓨터는 비트를 이해하고 다룰 수 있는 회로와 알고리즘을 사용하여 정보를 처리하고 표현한다.
비트는 컴퓨터의 기본적인 정보단위
컴퓨터 과학과 정보 이론의 핵심개념중 하나이다.
이해하고 활용하기 쉽기 때문에 컴퓨터 시스템과 데이터 표현을 다루는 데 필수적인 개념이다.
비트로 표현한 데이터 예시
숫자
- 00101010 은 42이다. 8비트로 표현되며 각 비트는 0 or 1 을 나타낸다.
문자
- 문자는 컴퓨터에서 비트로 표현되어 텍스트로 저장된다.
- ASCII 인코딩을 사용하여 각 문자에 대해 8비트가 할당된다.
- 문자 A 는 ASCII코드에서 65, 이진수로 01000001
색상
- 컴퓨터 그래픽에서 색상은 비트로 표현된다.
- 24비트 색상은 각각 빨강, 초록, 파랑 성분을 8비트씩 할당하여 표현한다.
- 이진수로 표현된 색상 값은 각 성분에 대한 밝기나 강도를 나타낸다
파일
- 파일은 컴퓨터에서 이진수 데이터로 저장된다.
- 이미지 파일은 픽셀 데이터로 구성되어 각 픽셀은 색상정보를 나타내는 비트로 표현된다.
바이트의 개념
바이트는 컴퓨터에서 데이터를 저장하고 처리하는 데 사용되는 단위이다.
바이트는 여러개의 비트를 모아놓은 형태, 보통 8개의 비트로 이루어져 있다.
- 바이트는 정보를 더 큰 단위로 나타내기 위해 사용된다.
- 비트는 단순히 0과 1의 두 가지 값을 나타내지만 바이트는 2의 8승인 256가지의 조합을 나타낼 수 있다. 이는 다양한 문자, 숫자, 기호 등 표현 할 수 있는 충분한 범위를 제공한다.
컴퓨터 메모리는 주로 바이트 단위로 관리된다.
- 메모리의 각 주소는 바이트 단위로 접근되며 프로그램이나 데이터는 바이트로 구성된 메모리에 저장된다.
- 파일 시스템에서도 파일의 크기는 일반적으로 바이트 단위로 표시된다.
바이트는 다양한 데이터를 표현하는데 사용된다.
- 텍스트 문서는 각 문자를 ASCII, UTF-8 or 다른 문자 인코딩 방식을 사용하여 바이트로 표현 및 저장이 된다.
- 이미지, 음악, 비디오 등 멀티미디어 파일도 바이트로 구성되며 특정한 파일 형식에 따라 바이트로 저장된다.
바이트는 컴퓨터의 데이터 저장과 처리에서 중요한 개념이다.
데이터를 바이트 단위로 나누어 저장, 처리 함으로 효율적인 데이터 관리와 다양한 데이터 유형의 처리를 가능하게한다.
bit와 Byte 정보 단위
| 단위 | 바이트 | 비트 |
| 비트(bit) | 1/8 바이트 | 1비트 |
| 바이트(Byte) | 1 바이트 | 8 비트 |
| 킬로 바이트(KB) | 1000 바이트 | 8000 비트 |
| 메가 바이트(MB) | 10 ^ 6 바이트 | 8 x 10^6 비트 |
| 기가 바이트 (GB) | 10 ^ 9 바이트 | 8 x 10^9 비트 |
| 테라 바이트 (TB) | 10 ^ 12 바이트 | 8 x 10^12 비트 |
비트(bit)와 바이트(Byte)는 모두 B로 시작하기에 비트는 소문자 b, 바이트는 대문자B로 표기
- 자료 표현 형식은 자료의 종류와 용도에 따라 다양하다.
- 일반적으로 텍스트, 숫자, 이미지, 음악, 비디오 등 다양한 유형의 자료를 저장하고 표현할 수 있다.
- 각 자료형식은 특정한 규칙과 구조를 가지며 컴퓨터는 이러한 구조를 이해, 처리 할 수 있도록 프로그래밍 되어야 한다.
텍스트 자료의 표현
표현하는 방법은 주로 문자 인코딩을 사용한다.
문자 인코딩은 문자를 컴퓨터가 이해할 수 있게 문자로 매핑하는 방식이다.
ASCII (American Standard Code for Information Interchange)
- 가장 일반적으로 사용되는 문자 인코딩 중 하나이다.
- ASCII는 7비트로 구성되며 각각 비트 조합은 128개의 고유한 문자를 나타낸다
- ASCII 코드는 영어 알파벳, 숫자, 특수 문자 등을 포함한다.
- 대문자 A는 ASCII에서 65, 이진수로 01000001 이다.
ASSCII는 1바이트(8비트를)를 모두 사용하지 않고 7비트만 사용한 이유
- 7비트로 표현된 ASCII 코드는 2^7 = 129개의 고유 한 값을 나타낼 수 있다.
- 영어 알파벳, 숫자, 특수 문자 등을 포함한 기본적인 문자 집합을 표현해주기에 충분하다.
- 초기 컴퓨터 시스템에서는 주로 영문 텍스트를 다구이 7비트로 구성되어 널리 사용되었다.
- 7비트 ASCII는 0부터 127까지의 값을 사용하여 문자를 나타낸다.
A는 65, a는 97로 표현되어 나머지 128부터 255까지의 값은 사용되지않거나, 다른 문자 인코딩 체계에 따라 확장문자나 특수문자로 사용 될 수 있다.
ASCII는 각 문자를 7비트로 표현함으로 총 128(=27)개의 문자를 표현할 수 있다.출처 : 스파르타 코딩클럽

ASCII문자코드
|
0100000
|
Space
|
1000000
|
@
|
1100000
|
`
|
|
0100001
|
!
|
1000001
|
A
|
1100001
|
a
|
|
0100010
|
“
|
1000010
|
B
|
1100010
|
b
|
|
0100011
|
#
|
1000011
|
C
|
1100011
|
c
|
|
0100100
|
$
|
1000100
|
D
|
1100100
|
d
|
|
0100101
|
%
|
1000101
|
E
|
1100101
|
e
|
|
0100110
|
&
|
1000110
|
F
|
1100110
|
f
|
|
0100111
|
‘
|
1000111
|
G
|
1100111
|
g
|
|
0101000
|
(
|
1001000
|
H
|
1101000
|
h
|
|
0101001
|
)
|
1001001
|
I
|
1101001
|
i
|
|
0101010
|
*
|
1001010
|
J
|
1101010
|
j
|
|
0101011
|
+
|
1001011
|
K
|
1101011
|
k
|
|
0101100
|
,
|
1001100
|
L
|
1101100
|
l
|
|
0101101
|
-
|
1001101
|
M
|
1101101
|
m
|
|
0101110
|
.
|
1001110
|
N
|
1101110
|
n
|
|
0101111
|
/
|
1001111
|
O
|
1101111
|
o
|
|
0110000
|
0
|
1010000
|
P
|
1110000
|
p
|
|
0110001
|
1
|
1010001
|
Q
|
1110001
|
q
|
|
0110010
|
2
|
1010010
|
R
|
1110010
|
r
|
|
0110011
|
3
|
1010011
|
S
|
1110011
|
s
|
|
0110100
|
4
|
1010100
|
T
|
1110100
|
t
|
|
0110101
|
5
|
1010101
|
U
|
1110101
|
u
|
|
0110110
|
6
|
1010110
|
V
|
1110110
|
v
|
|
0110111
|
7
|
1010111
|
W
|
1110111
|
w
|
|
0111000
|
8
|
1011000
|
X
|
1111000
|
x
|
|
0111001
|
9
|
1011001
|
Y
|
1111001
|
y
|
|
0111010
|
:
|
1011010
|
Z
|
1111010
|
z
|
|
0111011
|
;
|
1011011
|
[
|
1111011
|
{
|
|
0111100
|
<
|
1011100
|
\
|
1111100
|
|
|
|
0111101
|
=
|
1011101
|
]
|
1111101
|
}
|
|
0111110
|
>
|
1011110
|
^
|
1111110
|
~
|
|
0111111
|
?
|
1011111
|
_
|
1111111
|
DEL
|
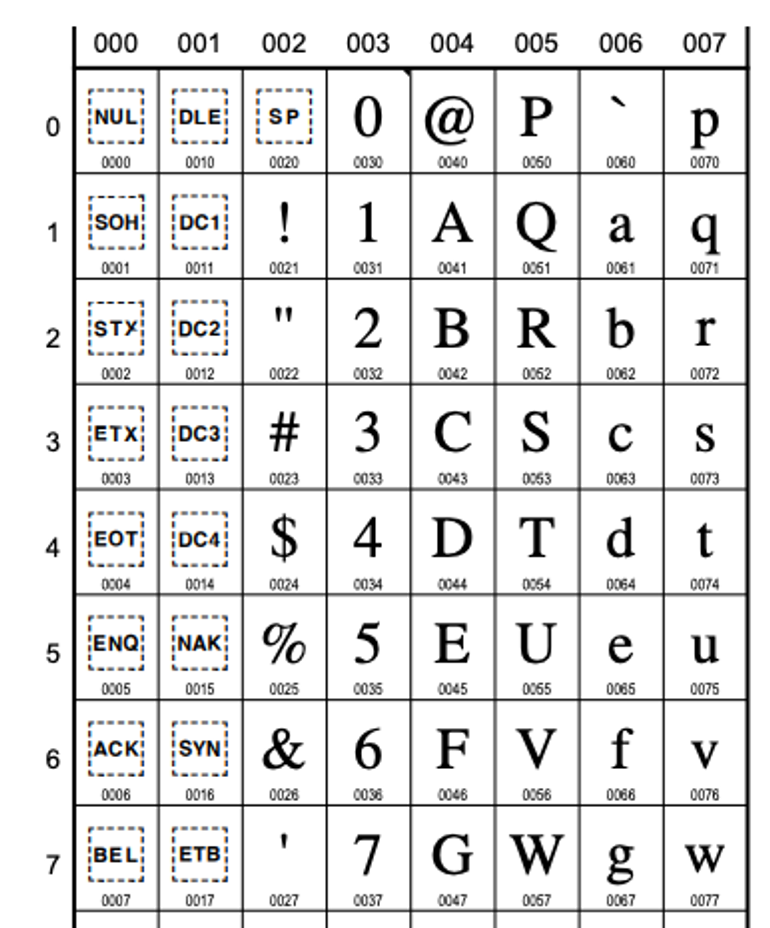
해당 문자의 왼쪽에 있는 2진코드가 ASCII코드가 되는것.
Ex) 문자 A의 왼쪽에 있는 1000001이 A의 ASCII코드
ASCII 코드 7비트에서 8비트 확장
- ASCII로 표현할 수 있는 문자들 외 추가적인 문자를 지원해야 할 필요성이 있어 기존 7비트에 1비트를 추가하여 8비트를 사용한 코드가 정의 되었다.
- 이런 코드를 확장(Extended) ASCII라 하는데 256(=28)개의 문자를 표현 할 수 있다.
- 기존 7비트 ASCII코드에는 가장 왼쪽에 0을 추가하여 8비트 형식이 되었다.

We를 8비트 형식의 ASCII로 나타낸것
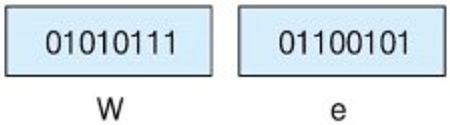
ASCII로는 영어와 몇가지 특수 문자 만을 표현할 수 있으나 각 나라별 언어를 표현할 수 없다.
유니코드와 UTF-8
유니코드(Unicode)
- 유니코드는 전 세계의 모든 문자를 고유한 코드 포인트로 나타낸 국제 표준이다.
- 유니코드는 U+로 시작하며 각 문자는 16진수 값으로 표현된 코드 포인트를 나타낸다.
- 각 문자에는 유니코드 코드 포인트라고 불리는 고유한 식별자가 할당되는데 이 코드 포인트는 16진수로 표현된다.
- 유니코드는 문자를 표현하는 방식에 대한 표준, 실제로 문자를 저장하거나 전송하는 방식에 대한 규정은 아니다.
Ex) A = U+0041과 같이 표현
UFT-8(Unicode Transformation Format-9)
- UTF-8은 유니코드를 컴퓨터에서 저장, 전송하기 위해 가변 길이 문자 인코딩 방식이다.
- UTF-8은 ASCII 문자에 대해 7비트로 표현, 다른 유니코드 문자는 8비트 이상으로 확장하여 표현하기에 이를 통해서 유니코드 문자를 효율적으로 저장하고 전송할 수 있다.
- UTF-8은 가변 길이 인코딩이기에 유니코드 포인트를 다양한 크기의 바이트 시퀀스로 변환한다. ASCII문자는 1바이트로 표현되며 추가적인 문자는 2바이트 부터 최대 4바이트 까지 사용 될 수 있다.
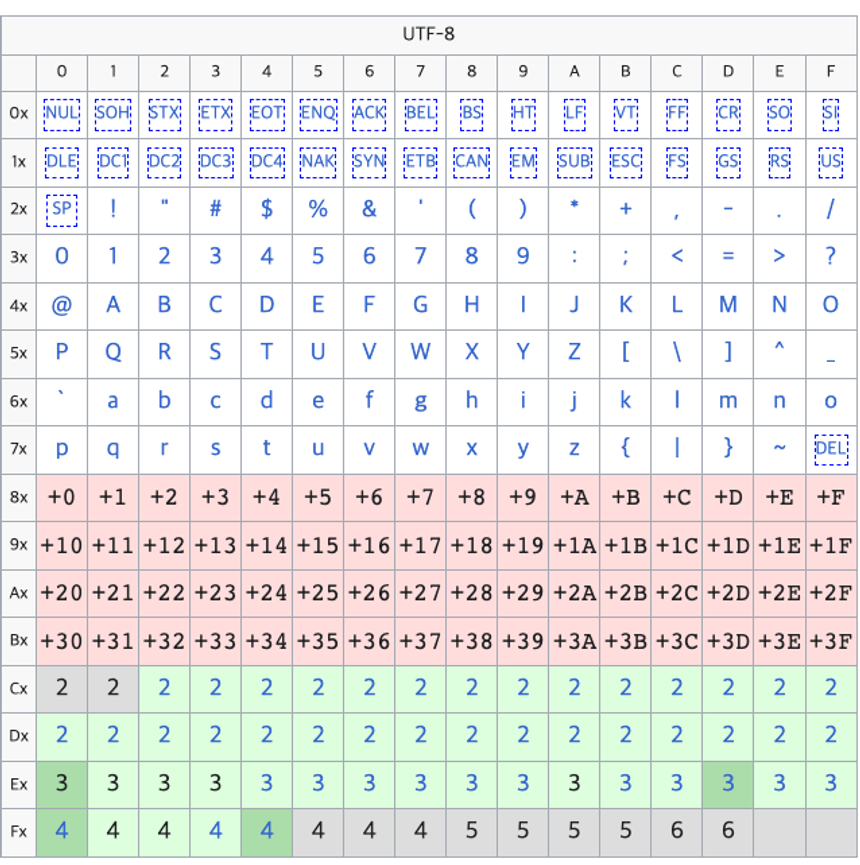
가변길이 구분 및 저장하는 방법
유니코드에 먼저 등록된 영어와 숫자같은 문자는 1byte, 그 뒤 등록된 문자는 4byte와 같이 차별적 혹은 가변적으로 할당하는 방법을 선택했다.
유니코드 별 Byte 할당 표

byte 별로 가변길이 구분을 짓기위하여 첫바이트에 표식으로 추가해준다.
- 1byte 는 0
- 2byte는 110
- 3byte는 1110
- 4byte는 11110
- 나머지 byte는 10
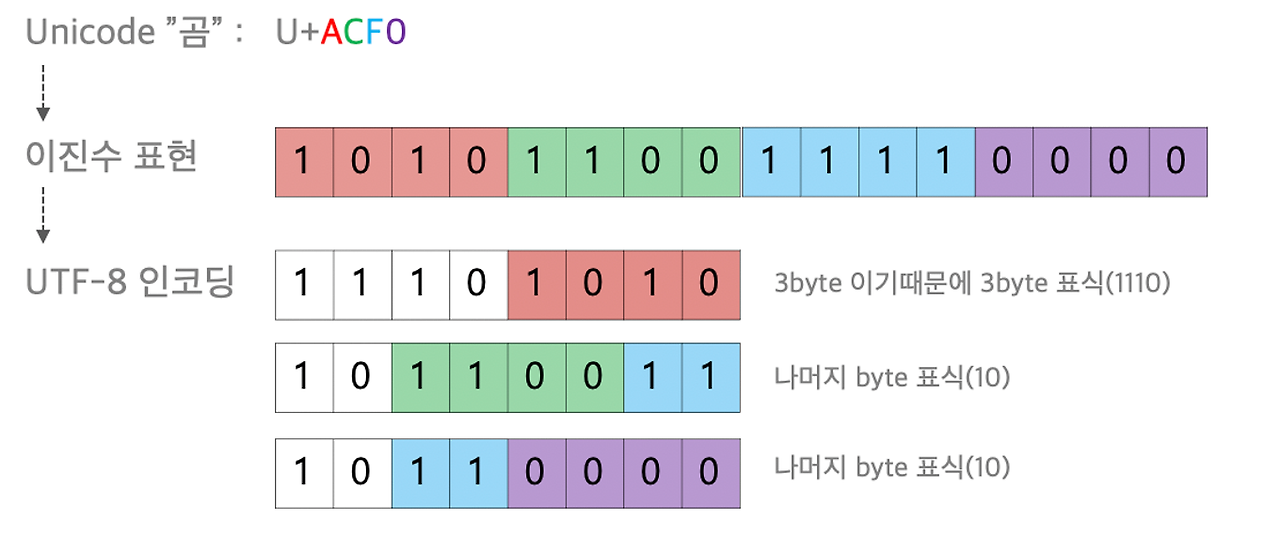
위의 예시를 보았을 경우 곰은 U+ACF0 이므로 표상 3바이트 범위에 속한다.
3바이트 작성법은 위 표에 나와 있듯이 1110xxxx/10xxxxxx/10xxxxxx로 그대로 받아적으면 된다.
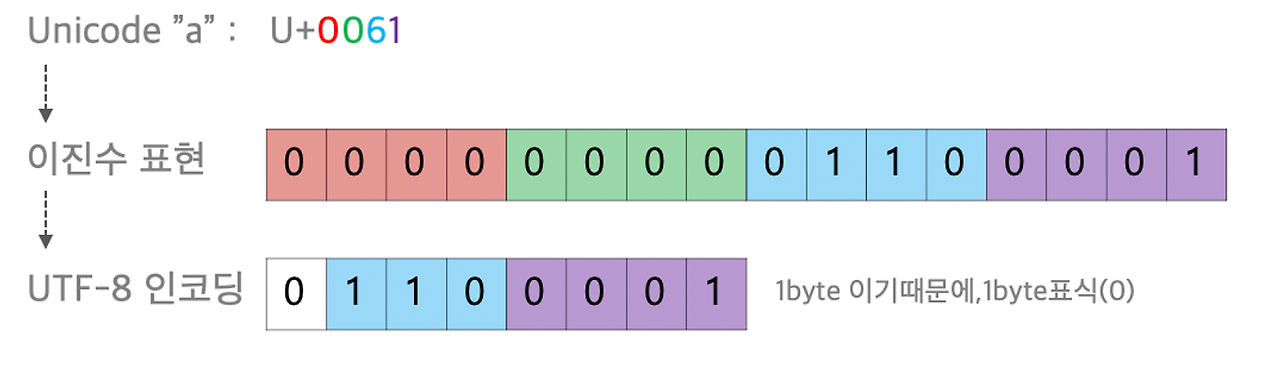
이 경우 a는 U+0061이므로 1바이트 범위에 속한다.
1바이트 표시형식을 참고하여 위와 같이 인코딩이 된다.
유니코드는 문자를 고유한 코드 포인트로 나타내는 국제 표준
UTF-8은 유니코드를 컴퓨터에서 효율적으로 저장, 전송하기 위한 인코딩 방식
UTF-8은 가변 길이 인코딩을 사용하여 다양한 크기의 바이트 시퀀스로 문자를 표현한다.
유니코드같이 큰바이트를 사용하면 모든 숫자나 문자 등을 표현할 수 있다.
굳이 프로그래밍을 하면 UTF8같이 다양한 데이터 타입을 사용하는 이유
- 컴퓨터는 받아들이는 모든 정보를 메모리에 저장한다.
- 예를 들면 1과 같이 작은 수를 표현하는데 4Byte를 사용해서 표현하게 되었을 경우 그만큼의 메모리가 낭비된다.
- 이처럼 메모리가 넉넉하지 못한 환경에서 동작하는 프로그램을 사용하게 되었을 경우에 효율적으로 메모리를 사용하는 것이 중요하다.
ASCII vs 유니코드 vs UTF-9
Hello 표현의 차이
ASCII
- ASCII는 7비트로 표현되는 문자 인코딩 방식이다
- Hello는 영어 알파벳으로만 이루어진 문장이므로 ASCII에서도 표현 할 수 있다.
- 각 문자는 ASCII 코드 포인트에 해당하는 값으로 표현된다.
- Hello는 ASCII코드로 72 101 108 108 111
유니코드
- 유니코드는 전세계의 모든 문자를 고유한 코드 포인트로 나타낸 표준이다.
- Hello는 영어 얼파벳으로만 이루어진 문장으로 유니코드에서도 표현 할 수 있다.
- 각 문자는 유니코드의 코드 포인트에 해당하는 값으로 표현된다.
- Hello는 유니코드로 U+0048 U+0065 U+006C U+006C U+006F
UTF-8
- UTF-8은 Unicode를 컴퓨터에서 효율적으로 저장하고 전송하기 위한 가변길이 문자 인코딩 방식이다.
- UTF-8은 ASCII와 호환되므로 ASCII문자는 그대로 표현된다
- Hello는 ASCII문자로 이루어진 문장이므로 UTF-8에서도 ASCII와 동일하게 표현된다
- UTF-8에서는 각 문자를 1바이트로 표현한다.
- Hello는 UTF-8로 72 101 108 108 111
ASCII는 7비트로 표현되는 문자 인코딩 방식
Hello 는 ASCII에서 각 문자의 코드 포인트 해당하는 값으로 표현.
유니코드는 전 세계 모든 문자를 고유한 코드포인트로 표현하는 표준
Hello는 유니코드에서 해당하는 값으로 표현
UTF-8은 유니코드를 효율적으로 저장, 전송하기 위한 가변길이 인코딩 방식
Hello는 UTF-8에서 ASCII와 동일하게 표현
"안녕" 표현의 차이
ASCII
- ASCII는 7비트로 표현되는 문자 인코딩방식이다.
- "안녕"은 한글로 이루어진 문장이므로 ASCII에서는 표현할 수 없다.
- ASCII는 영어 알파벳과 일부 특수 문자만을 표현할 수 있다.
유니코드
- 유니코드는 전 세계의 모든 문자를 고유한 코드 포인트로 나타내는 표준이다.
- "안녕"은 한글로 이루어진 문장이므로 유니코드에서도 표현할 수 있다.
- 각 문자는 유니코드의 코드 포인트에 해당하는 값으로 표현된다.
- "안녕"은 유니코드의 코드로 다음과 같이 표현된다. U+C548, U+B155
- 여기서 "안"은 U+C548, "녕"은 U+B155로 표현
UTF-8
- UTF-8은 유니코드를 컴퓨터에서 효율적으로 저장, 전송하기 위한 가변길이 문자 인코딩 방식이다.
- UTF-8은 ASCII와 호환되므로 ASCII문자는 그대로 표현된다.
- "안녕"은 한글로 이루어진 문장이므로 UTF-8에서도 표현된다.
- UTF-8에서 한글 문자는 3바이트로 표현된다.
- "안녕"은 UTF-8로 다음과 같이 표현된다.EC 95 88 EB 85 95
- "안"은 EC 95 88, "녕"은 EB 85 95
"안"의 이진수 표현
EC : 11101100
95 :10010101
88: 10001000
"녕"의 이진수 표현
EB : 11101011
85 : 10000101
95 : 10010101
- ASCII는 7비트로 표현되는 문자 인코딩 방식이므로 " 안녕"과 같은 한글 문장은 표현불가능하다.
- 유니코드는 전 세계의 모든 문자를 고유한 코드 포인트로 표현하는 표준,"안녕"은 유니코드에서 U+C548, U+B155
- UTF-8은 유니코드를 효율적으로 저장, 전송하기 위한 가변 길이 인코딩 방식, "안녕"은 UTF-8에서 3바이트로 표현
숫자 자료의 표현
컴퓨터에서 숫자를 표현하기 위해 비트의 조합을 사용한다.
각 비트는 0 or 1의 값을 가질수 있으며 여러비트를 조합하여 숫자를 나타낸다.
비트는 컴퓨터의 메모리나 레지스터와 같은 장치에 저장된다.
컴퓨터에서 숫자를 표현하는 방식은 여러가지가 있다.
가장일반적인 방식은 부호없는 정수, 부호 있는 정수, 실수를 표현하는 것.
부호 없는 정수
- 이진수를 사용하여 양수만을 표현한다.
- 각 비트는 0 or 1의 값을 나타내고 숫자의 크기를 나타내기 위해 자릿수가 높아질수록 2의 거듭제곱으로 증가한다.
- 8비트로 표현된 부호 없는 정수에서 숫자 42는 이진수로 00101010 으로 표현된다.
부호 있는 정수
- 부호 있는 정수는 양수와 음수를 모두 표현할 수 있다.
- 일반적으로 2의 보수 (Two's complement) 표현 방식을 사용한다.
- 양수는 부호 비트가 0으로 표현, 음수는 부호 비트가 1로 표현된다.
- 8비트로 표현된 부호 있는 정수에서 숫자 -42는 이진수로 11010110으로 표현된다.
실수
- 실수는 소수점을 가지는 숫자를 표현한다.
- 일반적으로 부동 소수점 표현 방식을 사용하고 가수와 지수를 이용하여 표현하는 방법이다.
- 부동 소수점은 정밀도와 범위를 조절할 수 있고 대부분 IEEE 754 표준을 따른다.
컴퓨터는 비트로 숫자를 저장, 처리 하기에 숫자의 크기, 정밀도, 부호 등을 조절하여 다양한 숫자 자료를 표현할 수 있다.
숫자를 이진수로 변환하고 이진수를 다시 숫자로 변환하여 컴퓨터에서 숫자를 표현하고 계산한다.
예시 및 차이점 비교
부호 없는 정수(unsigned integer)
- Java 또는 Python에서 부호없는 정수를 직접적으로 지원하지 않는다.
- 부호 없는 정수 값을 표현하고 싶은 경우에는 더 큰 데이터 유형 long(Python은 int)을 사용하거나 비트연산자와 함꼐 부호 없는 비트 연산을 수행할 수 있다.
Ex) 비트 연산자를 사용하여 두 개의 부호 없는 정수 값을 비트로 논리적 AND 연산 예시이다.
long a = 12L;
long b = 7L;
long result = a & b;
System.out.println("Result: " + result);
- A와 B는 부호없는 정수로 선언.
- 각각 부호 없는 64비트 정수 값 할당.
- a & b는 비트 AND연산 수행.
- 결과 result 변수에 저장 되어 결과는 4가 된다.
부호 있는 정수(signed integer)
- Java에서 byte, short, int, long
- Python 에서 int 데이터 유형으로 표현되어 이들은 양수와 음수의 정수 값을 표현할 수 있다.
Ex) 부호 있는 정수를 사용하여 두 개의 정수 값을 더하는 예시이다.
int a = 10;
int b = -5;
int sum = a + b;
System.out.println("Sum: " + sum);
- a 와 b는 부호 있는 정수로 선언.
- a에는 10, b에는 -5가 할당.
- 두 값을 더한 후 결과는 sum 변수에 저장.
- 결과는 5가 출력된다.
실수 (floating-point number)
- Java에서 실수는 float 과 double 데이터 유형으로 표현된다.
- 실수는 소수점을 가지는 수를 표현 할 수 있다.
Ex) 실수를 사용하여 두 개의 수를 나누는 예시이다.
double a = 10.5;
double b = 3.2;
double result = a / b;
System.out.println("Result: " + result);
- a 와 b 는 실수로 선언.
- a에는 10.5, b에는 3.2 할당
- 두 값을 나눈 후 결과는 result 변수에 저장
- 결과는 3.28125가 출력
비트 연산은 컴퓨터에서 비트 단위로 수행되는 연산이다.
이 연산은 이진수를 다룰 때 사용, 각 비트 상태에 따라 논리적인 계산을 수행한다.
비트 연산자 : AND(&), OR(ㅣ), XOR(^), NOT(~)등이 있다.
AND(&) 연산
- 두 비트가 모두 1인 경우 결과 비트가 1이된다. 그 외 경우는 0이 된다.
- Ex) 1010& 1100 결과는 1000.
OR(ㅣ)연산
- 두 비트 중 하나 이상이 1인 경우 결과 비트가 1이된다. 두비트가 모두 0인 경우 결과 비트가 0이 된다.
- Ex) 1010 ㅣ 1100 결과는 1110.
XOR(^) 연산
- 두 비트가 서로 다른 경우 결과 비트가 1이 된다. 두 비트가 모두 같은 경우 결과 비트가 0이된다.
- Ex) 1010 ^ 1100의 결과는 0110
NOT(~) 연산
- 비트를 반전시킨다. 1은 0 으로 0은 1로 변환
- Ex) ~1010의 결과는 0101
비트 연산은 다음과 같은 상황에서 사용
- 비트 단위의 플래그 설정 및 해제
- 비트마스크를 사용한 데이터 필터링 or 선택
- 데이터의 압축 or 암호화 알고리즘에서 사용
비트 연산은 컴퓨터의 원시적이고 효율적인 수준의 연산이므로 저수준의 작업에 사용된다.
멀티미디어 자료의 표현
컴퓨터에서 멀티미디어 자료를 표현하기 위해서는 특정 파일 형식을 사용한다.
각각의 멀티미디어 자료 유형에는 해당형식에 맞는 특정 압축, 인코딩 및 알고리즘을 사용하여 데이터를 저장하고 표현한다.
이미지
- 이미지는 비트맵(bitmap) or 벡터(vector)형식으로 표현된다.
- 비트맵 이미지는 픽셀로 구성되며 각 픽셀은 색상 정보를 나타내는 숫자로 표현된다.
- JPEG(Joint Photographic Experts Group) 와 PNG(Portable Network Graphics)는 흔히 사용되는 비트맵 이미지 형식
- 벡터이미지는 수학적인 식이나 명령어로 구성되며 확대 및 축소에 따라 해상도가 유지된다.
- SVG(Scalable Vector Graphics)가 대표적인 벡터 이미지 형식이다.
오디오
- 오디오는 일련의 연속적인 음향 신호로 표현된다.
- PCM(Pulse Code Modulation)은 가장 기본적인 오디오 표현 방식으로 아날로그 오디오 신호를 디지털 신호로 변환한다.
- WAV(Waveform Audio File Format)와 AIFF(Audio Interchange File Format)는 PCM 오디오를 저장하기 위해 사용되는 형식이다.
- 압축된 오디오 형식으로 MP3(MPEG Audio Layer - 3) 와 AAC(Advanced Audio Coding)등이 있다.
동영상
- 동영상은 연속적인 이미지 프레임의 시퀀스로 표현된다.
- 동영상은 주로 비트맵 이미지와 오디오를 조합하여 구성된다.
- AVI(Audio Video Interleave), MP4(MPEG-4 Part 14) 및 MKV(Matroska) 등의 형식이 사용된다.
- 동영상 압축 형식으로는 MPEG(Moving Picture Experts Group) 시리즈, H.264, VP9, AV1 등이 있으며 이러한 압축 알고리즘은 비디오 데이터를 효율적으로 압축하여 저장 및 전송할 수 있도록 한다.
컴퓨터에서 멀티미디어 자료를 표현하기 위해서는 해당 유형의 데이터를 해석, 디코딩하고 필요한 경우 재생성 및 렌더링 하는 소프트웨어 or 하드웨어가 필요하다.
반응형
'Computer Science' 카테고리의 다른 글
| 스파르타 코딩클럽(부트캠프) 9장 OSI 7계층 (0) | 2024.03.27 |
|---|---|
| 스파르타 코딩클럽(부트캠프) 8장 자료구조의 동작과 활용 (2) | 2024.03.26 |
| 스파르타 코딩클럽(부트캠프) 6장 DBMS(데이터베이스 관리 시스템)의 기능과 종류 (1) | 2024.03.22 |
| 스파르타 코딩클럽(부트캠프) 5장 DB(데이터베이스) 구조와 유형 (0) | 2024.03.21 |
| 스파르타 코딩클럽(부트캠프) 4장 프로세스 쓰레드와 쓰레드 (0) | 2024.03.20 |
'Computer Science' Related Articles
more



