
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 업로드 #lambda #함수 #모바일 이미지 #썸네일 이미지
- 공간복잡도 #공간자원 #캐시메모리 #SRAM #DRAM #시간복잡도
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #KDT #기본문법 #데이터베이스 #Computer #Science #CPU #메모리
- 쓰레드 #쓰레드풀 #프로세스
- aws #아키텍트 #과정 #vpc #인프라 구축 #rds #endpoint #cloudwatch #monitoring
- 썸네일 #이미지
- aws #아키텍트 #과정 #vpc #인프라 구축 #auto scailling #lauch template #ec2 instace #private #subnet
- aws #아키텍트 #과정 #vpc #인프라 구축 #s3 #bucket #객체 스토리지 #objects storage #events #upload #알림
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- aws #아키텍트 #과정 #vpc #인프라 구축 #aurora #database #rds #rdbs #load #balancer #web #page #haproxy
- aws #아키텍트 #과정 #vpc #인프라 구축 #db #장애조치 #reand only #replica #events
- aws #아키텍트 #과정 #vpc #인프라 구축 #alb #load balancer #t.g #target #group #haproxy #high ability #db #replica #region
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #OSI #ISO #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- aws #아키텍트 #과정 #vpc #인프라 구축 #amazon sns #server #less #architecture
- aws #아키텍트 #과정 #vpc #인프라 구축 #t.g #target group #alb #application #load #balancer #web #server
- aws #아키텍트 #과정 #vpc #인프라 구축 #haproxy #round robin #process #high ability #auto scailling #app server #launch template
- aws #아키텍트 #과정 #vpc #인프라 구축 #rds #replica #복제본 #aurora #database #고가용성
- aws #아키텍트 #과정 #vpc #인프라 구축 #haproxy #고가용성 #테스트 #alb #application #load balancer #application
- aws #아키텍트 #과정 #vpc #인프라 구축 #second nat #gateway #routing table #route53 #고가용성 #private subnet #
- 비트 #바이트 #이진수
- aws #아키텍트 #과정 #vpc #인프라 구축
- aws #아키텍트 #과정 #vpc #인프라 구축 #php #alb #application #load #balancer #security #group #igw #ec2 #vpc #virtual #private #cloud
- aws #아키텍트 #과정 #vpc #인프라 구축 #sqs #trigger #python3.9 #패키지 #
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #웹개발
- aws #아키텍트 #과정 #vpc #인프라 구축 #sqs #message #queue #sns구독
- aws #아키텍트 #과정 #vpc #인프라 구축 #s3 #bucket #객체 #스토리지 #isci #이미지 #업로드
- aws #아키텍트 #과정 #vpc #인프라 구축 #ec2 #instance #launch #template #생성 #ami #amazone #machine #image
- 프로세스 #CPU #시공유 #커널
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- Today
- Total
요리사에서 개발자
스파르타 코딩클럽(부트캠프) 8장 자료구조의 동작과 활용 본문
자료구조에는 배열, 리스트, 벡터, 큐, 스택, 해시 테이블 등이 있다.
- 배열은 연속적인 메모리 위치에 데이터를 저장하는 자료구조
- 리스트는 노드로 연결된 데이터를 저장하는 자료구조
- 벡터는 연속된 저장공간을 늘려가며 데이터를 저장하는 자료구조
- 큐, 스택은 입/출력 위치에 제약을 두고 성능을 높이는 자료구조
- 해시테이블은 키와 값의 쌍을 저장하는 자료구조
자료와 자료구조
텍스트 자료의 표현
ASCII
- 가장 일반적으로 사용되는 문자 인코딩 중 하나는 ASCII (American Standard Code for Inforamation Iterchange)이다.
- ASCII는 7비트로 구성, 각각의 비트 조합은 128개의 고유한 문자를 나타낸다
- ASCII 코드는 영어 알파벳, 숫자, 특수문자 등을 포함한다.
- 대문자 'A'는 ASCII코드에서 65에 해당하는 값으로 표현, 이진수로 01000001 이다.
- ASCII는 각 문자를 7비트로 표현하므로 총 128(=27)개의 문자를 표현할 수 있다.

|
000
|
Space
|
1000000
|
@
|
1100000
|
`
|
|
0100001
|
!
|
1000001
|
A
|
1100001
|
a
|
|
0100010
|
“
|
1000010
|
B
|
1100010
|
b
|
|
0100011
|
#
|
1000011
|
C
|
1100011
|
c
|
|
0100100
|
$
|
1000100
|
D
|
1100100
|
d
|
|
0100101
|
%
|
1000101
|
E
|
1100101
|
e
|
|
0100110
|
&
|
1000110
|
F
|
1100110
|
f
|
|
0100111
|
‘
|
1000111
|
G
|
1100111
|
g
|
|
0101000
|
(
|
1001000
|
H
|
1101000
|
h
|
|
0101001
|
)
|
1001001
|
I
|
1101001
|
i
|
|
0101010
|
*
|
1001010
|
J
|
1101010
|
j
|
|
0101011
|
+
|
1001011
|
K
|
1101011
|
k
|
|
0101100
|
,
|
1001100
|
L
|
1101100
|
l
|
|
0101101
|
-
|
1001101
|
M
|
1101101
|
m
|
|
0101110
|
.
|
1001110
|
N
|
1101110
|
n
|
|
0101111
|
/
|
1001111
|
O
|
1101111
|
o
|
|
0110000
|
0
|
1010000
|
P
|
1110000
|
p
|
|
0110001
|
1
|
1010001
|
Q
|
1110001
|
q
|
|
0110010
|
2
|
1010010
|
R
|
1110010
|
r
|
|
0110011
|
3
|
1010011
|
S
|
1110011
|
s
|
|
0110100
|
4
|
1010100
|
T
|
1110100
|
t
|
|
0110101
|
5
|
1010101
|
U
|
1110101
|
u
|
|
0110110
|
6
|
1010110
|
V
|
1110110
|
v
|
|
0110111
|
7
|
1010111
|
W
|
1110111
|
w
|
|
0111000
|
8
|
1011000
|
X
|
1111000
|
x
|
|
0111001
|
9
|
1011001
|
Y
|
1111001
|
y
|
|
0111010
|
:
|
1011010
|
Z
|
1111010
|
z
|
|
0111011
|
;
|
1011011
|
[
|
1111011
|
{
|
|
0111100
|
<
|
1011100
|
\
|
1111100
|
|
|
|
0111101
|
=
|
1011101
|
]
|
1111101
|
}
|
|
0111110
|
>
|
1011110
|
^
|
1111110
|
~
|
|
0111111
|
?
|
1011111
|
_
|
1111111
|
DEL
|
ASCII로 표현할 수 있는 문자들 외 추가적인 문자를 지원해야 할 필요성이 있어 기존 7비트에 1비트를 추가하므로 8비트를 사용한 코드가 정의 되었다.
- 이런 코드를 확장(extended) ASCII 라 한다.
- 256(=28)개의 문자를 표현할 수 있다.
- 기존 7비트 ASCII 코드에는 가장 왼쪽에 0을 추가하여 8비트 형식이 되었다.

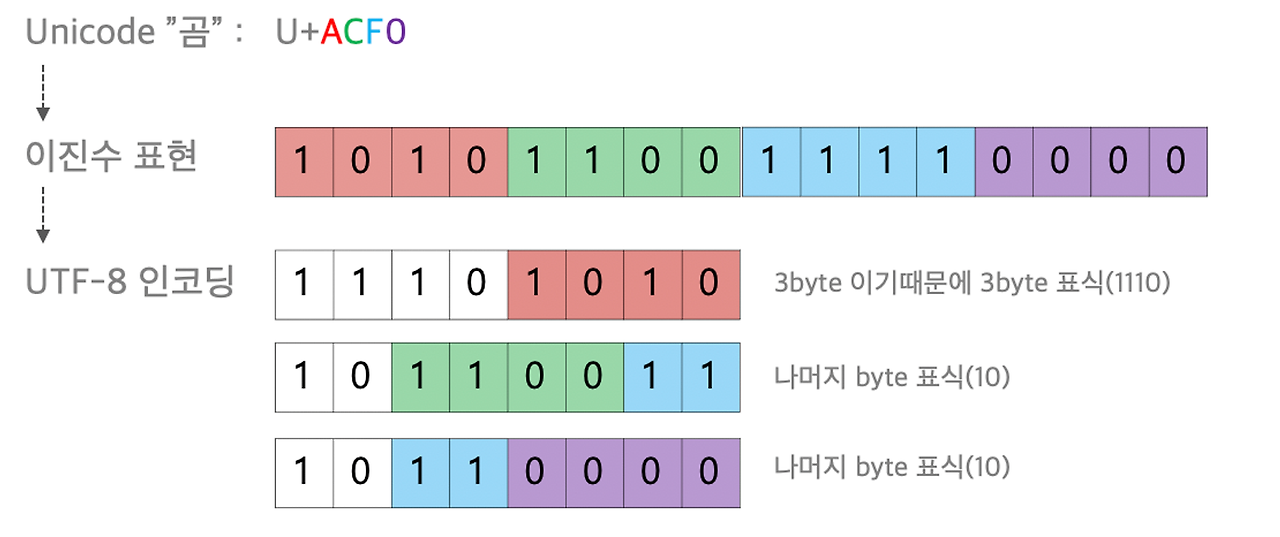
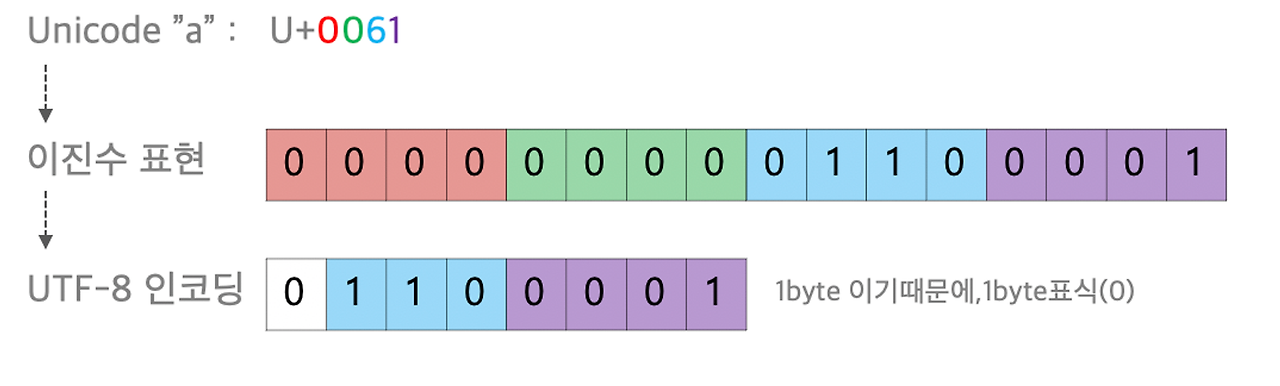
유니코드와 UTF-8
유니코드에 먼저 등록된 영어와 숫자같은 문자는 1byte, 그 뒤에 등록된 문자는 4byte와 같이 차별적 혹은 가변적으로 할당하는 방법을 선택했다.
유니코드별 Byte 할당표

- byte 별 가변길이 구분
- 1byte 는 0으로 시작
- 2byte는 110으로 시작
- 3byte는 1110으로 시작
- 4byte는 11110으로 시작
- 나머지 byte는 10으로 시작
숫자 자료의 표현
컴퓨터에서 숫자를 표현하기 위해 비트의 조합을 사용한다.
각 비트는 0 또는 1의 값을 가질수 있고 여러비트르 조합하여 숫자를 나타낸다.
비트는 컴퓨터의 메모리나 레지스터와 같은 장치에 저장된다.
컴퓨터에서 숫자를 표현하는 방식 중 가장 일반적인 방식은 부호 없는 정수, 부호 있는 정수, 실수를 표현한다.
부호 없는 정수
- 이진수를 사용하여 양수만을 표현한다.
- 각 비트는 0 또는 1의 값을 나타내며 숫자의 크기를 나타내기 위해 자릿수가 높아질수록 2의 거듭제곱으로 증가한다
- Ex) 8비트로 표현된 부호 없는 정수에서 숫자 42는 00101010으로 표현
부호 있는 정수
- 부호 있는 정수는 양수와 음수를 모두 표현할 수 있다.
- 일반적으로 2의 보수(Two's complement)표현 방식을 사용한다.
- 양수는 부호 비트가 0으로 표현, 음수는 부호 비트 1로 표현
- Ex) 8비트로 표현된 부호 있는 정수에서 숫자 -42는 이진수로 11010110
실수
- 실수는 소수점을 가지는 숫자를 표현한다.
- 일반적으로 부동 소수점 표현 방식을 사용한다. 이는 가수와 지수를 이용하여 실수를 표현하는 방법이다.
- 부동 소수점은 정밀도와 범위를 조절할 수 있고 대부분 IEEE 754 표준을 따른다.
컴퓨터는 비트로 숫자를 저장, 처리하기에 숫자의 크기, 정밀도, 부호 등을 조절하여 다양한 숫자 자료를 표현할 수 있다.
숫자를 이진수로 변환, 다시 이진수를 숫자로 변환하여 컴퓨터에서 숫자를 표현하고 계산한다.
선형/비선형 자료구조
아래 자료들은 연속적인 공간에 단순한 규칙을 정하고 데이터를 저장하는 단순구조의 자료구조이다.
선형구조 or 비선형구조의 특징
- 더 복잡하고 큰 데이터를 저장하고 빠르게 연산하기 위해.
- 복잡한 데이터를 단순 구조로 저장할 경우 삽입/ 삭제가 어려움을 극복하고자

선형 자료구조
데이터가 저장 순서대로 저장되는 자료구조이다.
- 배열은 데이터를 연속적인 메모리 공간에 저장하는 자료구조
- 연결 리스트는 데이터가 노드로 연결된 형태로 저장되는 자료구조
- 스택은 데이터를 마지막에 삽입, 마지막에 삭제하는 자료구조
- 큐는 데이터를 첫 번째 삽입, 첫 번째 삭제하는 자료구조
비선형 자료구조
데이터가 저장 순서가 아닌 규칙에 따라 저장되는 자료구조이다.
- 트리는 데이터가 계층적으로 저장되는 자료구조
- 그래프는 데이터가 노드와 엣지로 연결된 형태로 저장되는 자료구조
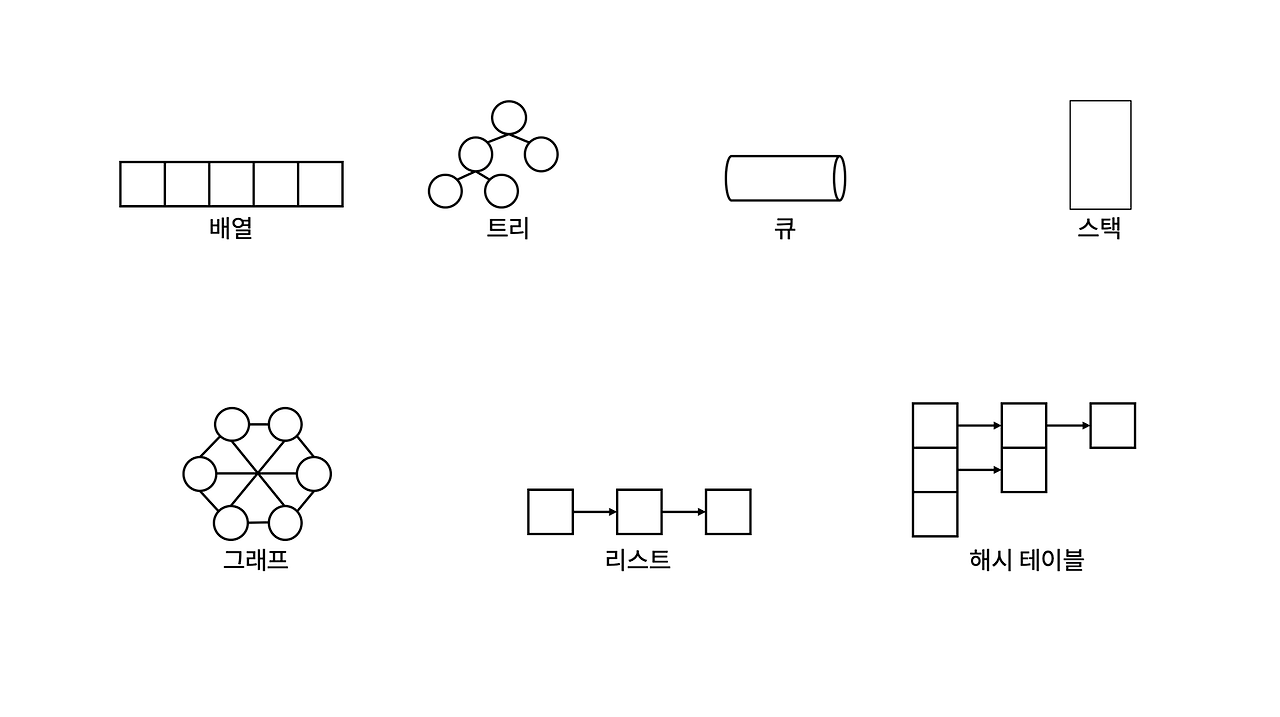
자료구조
Array (배열)
배열은 연속적인 메모리로 위치에 데이터를 저장하는 자료구조이다.
배열은 데이터의 순서를 유지할 수 있고 데이터에 빠르게 접근할 수 있다.
배열의 크기는 고정되어 있기에 데이터가 많아지면 배열을 재할당 해야한다.
배열이 필요한 이유
서로 연관된 데이터라 해도 이를 프로그램상 표현하기위한 방법은 변수를 여러개 만드는것.
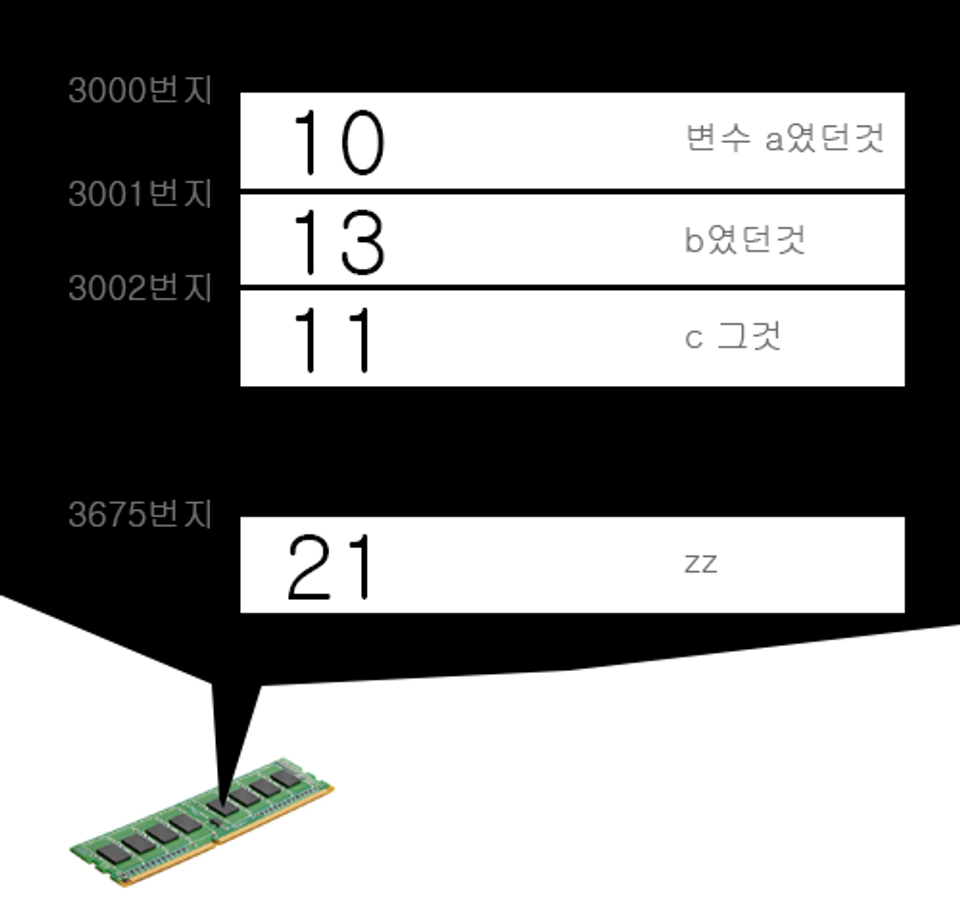
Ex) 오늘의 기온 데이터를 시간 순서에 따라 676개로 나눈것
int a = 10;
int b = 13;
int c = 11;
...
int zz = 21;
이처럼 코드를 작성했을 경우
- 이해하기 힘들다.
- 코드길이가 길어질 것이다.
- 변수명 창작의 고통(어제 날짜 기온 표현)
서로 연관된 데이터이기에 메모리상 연속구간에 차례대로 넣고 해당 연속 구간의 시작점과 끝이 어딘지만 알면된다.
실제 배열로 만든 자료형(int, double 등) 에따라 표현하기 위한 메모리 크기가 달라지며 이는 운영체제, CPU 등 다양한 변수로 인해 달라진다.
- boolean은 실제 1bit만 필요하나 실제로 1byte 혹은 int형과 동일한 크기를 차지하기도 한다.
- C언어 처럼 size of 함수를 통해 현재 프로그램에서 판단하는 크기를 얻을 수 있고 자바처럼 신경안써도 되는 경우도 있다.
arr이라는 변수에 3000이라는 주소값만 저장한다면 기존에 a,b,c...zz까지 676개의 변수로 각각 표현해야 했던 데이터를 arr에 담겨진 3000이라는 주소값, 총 676개라는 정보만 있으면 표현할 수 있다.
- 첫번째 데이터 a에 접근 ->3000
- 두번째 데이터 b에 접근 -> 3000+1
- 마지막 데이터 zz에 접근 -> 3000+675
자바 배열
- { } 또는 new int[676] 처럼 배열이 생성되면 메모리상 어딘가 연속된 공간에 위 그림과 같은 배열이 생성되며 arr에는 해당 주소가 리턴되서 들어간다.
- 그 후 arr[n]과 같이 n+1번째 데이터에 접근할 수 있다.(배열 인덱스의 시작은 0이므로)
자바시스템은 arr[n]을 호출 할 시 곱셈연산을 통하여 메모리에 int형 사이즈의 n배를 곱한 주소 데이터를 가져오게 된다.
int[] arr = {10, 13, 11, ..., 21};
arr[0]; // 변수 a 였던것
arr[1]; // 변수 b 였던것
arr[675]; // 변수 zz 였던것
C언어 배열
- raw한 언어인 C언어를 보았을 경우 int형 사이즈 위에도 사용하였듯 시스템마다 다를 수 있기에 sizeof 함수를 통해 가져와 메모리에 원하는 사이즈의 연속공간을 가져오는 malloc 함수로 공간을 가져온다.
- 이후 자바에서 배열 사용하는 것처럼 arr[n]으로도 사용이 가능하고 *arr, *arr+1처럼 +n을 통해 데이터를 가져올 수 있다.
int* arr = malloc(sizeof(int) * 676);
arr[0] = 10;
arr[1] = 13;
...
arr[675] = 21;
*arr;// 변수 a 였던것
*arr+1;// 변수 b 였던것
*arr+675;// 변수 zz 였던것
참조형 타입 변수의 배열
- 자바에 String은 String[] str = new string[5]; 식으로 string 배열을 만들수 있다. 연속된 공간을 할당받아 접근한다면 String은 늘려서 작성할 수 있다.
- 자바 or 대부분의 언어들은 자료형을 Primitive type(원시형) reference type(참조형)으로 나뉘는데 일반적으로 알고있는 소문자로 시작(int, boolean, byte, long, double, char 등)이 원시형이고 메모리상에 실제값 그 자체가 저장된다.
- 이외 모든 타입은 참조형(int[] 참조형)으로 이 타입은 주소값을 저장한다.
참조형 타입에 대한 배열에 실제 데이터는 연속적이지 않으나 실제 데이터가 있는 주소값을 저장하는 부분이 연속적이다.
String[] str = {"ABCD", "DDDDDDDD", "배열이다", "NN"};

배열의 기능, 동작
개발자에게 이런 개념이 필요한 이유는 언제 배열, 리스트, map, set 등을 사용할려면 기본 동작 원리와 개념을 이해해야한다.
배열의 특징
- 메모리 순서대로 순서가 정해져있다.
- 연속된 공간을 미리 정해서 사용한다.(확정된 메모리 공간을 할당받아 사용하기에)
- N번째 데이터에 접근 하기 위해서 복잡한 과정이 제외되고 덧셈과 곱셈 한번이면 가능하다(n번째 데이터 접근 : 시작 주소 +(n-1) *해당자료형 크기)
갯수가 확정이 된 경우 배열이 쓰일 수 있다.
CRUD 배열의 동작
Create
new int[5];로 만들어져있는 데이터에 새로운 6번째 데이터를 새로 배열에 넣으려고한다
메모리 연속된 공간을 사용중이니 메모리에 연속된 공간을 늘리면 된다? 가 아니다.
이미 해당 공간이 사용중인지 알수 없기에 사용하면 안되며 자바에서는 그렇게 할수 없다
유일한 방법은 새로운 연속된 공간을 다시 할당받아 기존에 있던 데이터를 모두 새로운 곳으로 옮기는 방법
int[] arr = new int[5];
arr[0] = 1;
...// 무언가 넣음int[] tmp = new int[6];
for (int i = 0; i < arr.length; i++) {
tmp[i] = arr[i];
}
arr = tmp;
Read
- 몇번째 데이터라도 덧셈과 곱셈 한번씩이면 접근 할 수 있기에 매우 빠르게 접근할 수 있다.
Update
- Read와 마찬가지 매우 쉽게 접근해서 수정할 수 있다.
Delete
- Create처럼 어렵다.
- Ex) int[] arr = new int[5]; 에서 arr[3]을 제거한다.
- Create 예시처럼 new int[4];를 만든 후 복사하여 넣어야 한다.
- 공간자체는 줄이지 않아도 arr[3]이후 모든 값을 한칸씩 앞으로 당겨줘야한다.
예외
배열의 크기를 사용하는 데이터의 갯수와 관계없이 유지해도 되고 마지막 데이터를 삭제하는 경우라면 한번에 가능하다.
배열의 시간복잡도
데이터 읽기, 수정 : O(1)
데이터 추가, 삭제 : O(N)
예외 : 배열의 빈 공간이 존재하는걸 허용하며 짜는 경우라면 마지막 데이터의 추가, 삭제는 O(1)
최종 데이터 갯수가 확정되어 있으며 데이터 읽기와 수정이 많고 새로운 데이터가 추가되거나 삭제되지 않는 경우는 배열을 사용하기 적합하다.
LinkedList(리스트)
- 링크드 리스트는 일반적인 리스트로 불리며, 노드로 연결된 데이터를 저장하는 자료구조이다.
- 링크드 리스트는 데이터의 순서를 유지할수 없으나 데이터를 추가, 삭제하는것이 쉽다.
- 배열과 달리 배열의 크기를 지정하거나 변경할 필요가 없다.
리스트는 배열처럼 데이터를 순서대로 표현하는 자료구조 중 하나이며 구현 방법에는 큰 차이가 있다.
배열
- 메모리 상에 연속된 공간을 미리 할당받아 메모리 상에 데이터를 순서대로 넣어 만든 구조이다.
리스트
- 메모리 상에 데이터가 어디에 있던 신경쓰지 않는다
Ex) data = [12, 3, 11, -2]
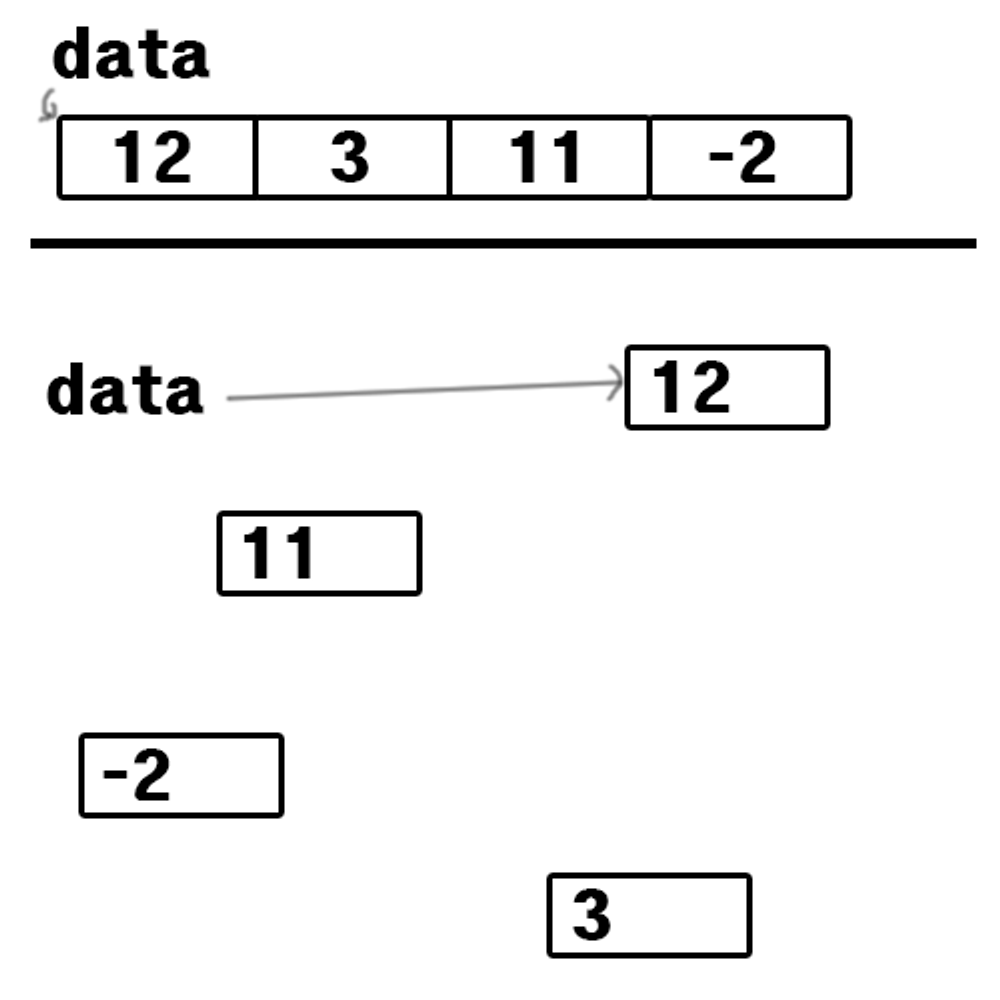
위처럼 메모리 상에 순서대로 들어가 있는것이 배열
아래쪽에 메모리 상에 흩뿌려져 있는것이 리스트
배열과 리스트 모두 data 라는 변수는 첫번째 데이터의 위치만을 가리키고 있다.
- 배열은 메모리 자체에 순서대로 들어가 있으므로 다음 데이터는 물론이고 n번째 데이터도 쉽게 알수 있다.
- 리스트는 현재 그림상 리스트에서 첫번째 데이터 12의 위치는 알 수 있으나 n번째 데이터는 물론 다음 데이터의 위치도 알수 없다.

각 위치의 메모리상 번지수를 작성하므로
- 기존 데이터를 1칸으로 표현할 때는 알 수 없었으나 2칸으로 나누어 데이터와 번지수를 작성
- 각 데이터를 순서대로 보며 2번째 칸의 번지수를 확인해보면 다음데이터의 위치를 알 수 있다.
허나 배열로 표현할때와 다르게 시작지점에서 n번째 데이터가 어디있는지 바로 알기 어렵다.
메모리에 연속된 공간을 쓰지 않는 경우에 빠르게 찾을 수 없기 때문이다.
알고리즘이나 자료구조의 선택에는 trade-off 가 있다.
DB에서 인덱스를 걸면 검색이 빨라지는 대신 삽입, 삭제가 느려지고 인덱스를 만들어 두기 위하여 메모리 손실이 나는것과 마찬가지이다.
Create - 기존에 없는 데이터를 새로 삽입하는 경우
시작 : 3번째 데이터 22 뒤에 데이터를 추가

head에서 3번째 데이터의 위치를 알 수 없기에 리스트를 따라 3번쨰 데이터 까지 가야한다.

해당 위치에 데이터를 넣어준다.
- 배열은 메모리상에 연속된 공간을 유지해야하기에 중간에 바로 넣을 수 없다.
- 더 큰 새로운 배열을 만든 후에야 다른것들을 복사하여 넣을 수 있다.
- 리스트는 메모리상 위치가 상관 없기에 서로간 화살표를 조정하면 가능하다.
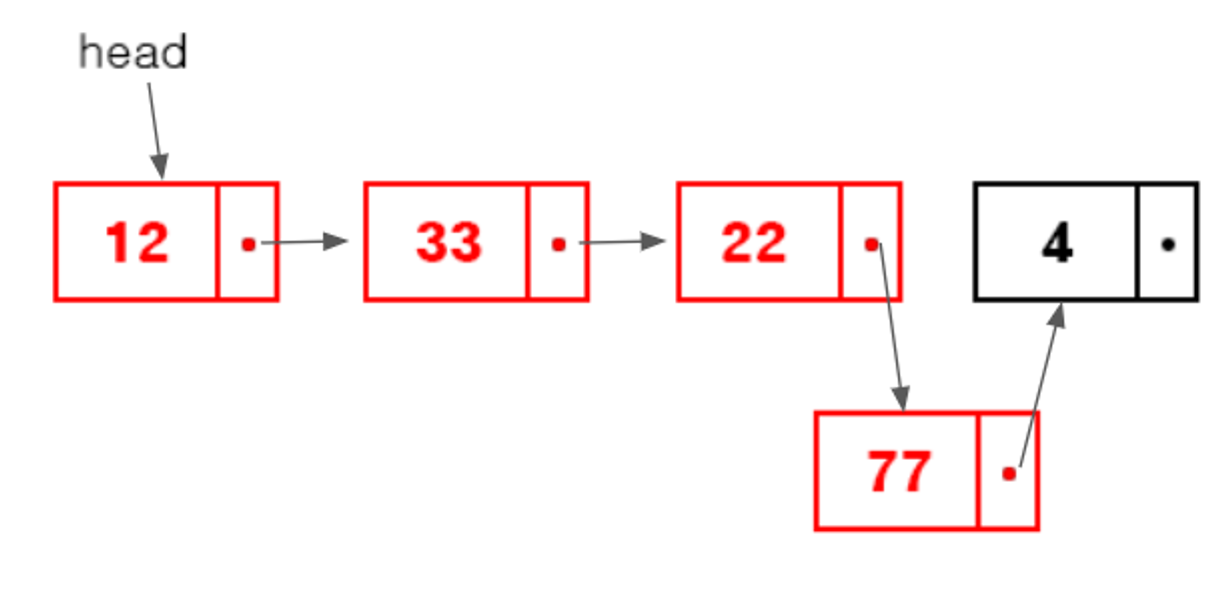
그렇기에 배열과 똑같이 O(N)의 시간복잡도를 가지게 된다.
중간에 데이터를 삽입하는 경우 배열이나 리스트나 비슷하다.
리스트는 일반적 맨 앞 or 맨 뒤에 데이터를 추가하기에
- head로 시작점을 표시, tail이라고 맨 뒤를 표시하는 변수도 존재한다.
- 따라서 한번만에 시작이나 끝 지점을 알 수 있고 바로 데이터를 넣을 수 있다.
리스트 Create 시간 복잡도
리스트의 중간에 데이터를 넣을 경우 : O(N)
맨 앞 or 맨뒤에 넣을 경우 : O(1) -이 경우가 많다
Read, Update - 데이터의 값을 확인 or 바꾸는 경우
시작 : 3번째 데이터를 확인 or 바꾸려면 head에서 알 수 없어 순서대로 확인하거나 바꿔야 한다.
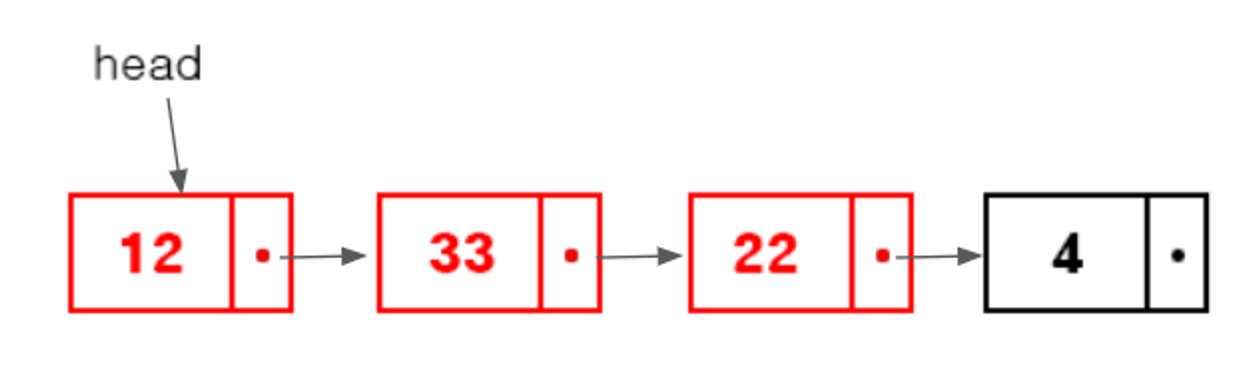
리스트 Read/Update 시간 복잡도
맨앞 or 맨뒤에 데이터를 확인하거나 바꿀 경우 : O(1)
중간 데이터를 확인 or 바꿀경우 : O(N) - 이 경우가 많다.
Delete - 데이터를 삭제
3번째 데이터인 22를 삭제한다면 3번째 데이터 까지 찾아간 후에 22대신 22다음 데이터를 연결하면 된다.
22는 이후에 Gavage Collector 가 제거되니 신경쓰지 않아도 된다.

리스트 Delete 시간복잡도
중간의 데이터를 삭제할 경우 : O(N)
맨앞 or 맨 뒤 데이터를 확인하거나 바꿀 경우 : O(1) - 이 경우가 많다.
배열과 리스트 사용시기
시간 복잡도와 상황에 맞게 사용하면 된다.
리스트
- 일반적으로 데이터의 추가, 삭제가 많은 경우 효율이 좋다.
배열
- 데이터가 자주 추가, 삭제되지 않으며 읽고 수정하는 경우가 많은 경우 효율이 좋다.
배열과 리스트의 원리를 이해하며 현재 로직에 맞는것을 사용하면 된다.
ArrayList(벡터)
LinkedList vs ArrayList vs Vector
- 자바를 사용한 사람들은 ArrayList와 LinkedList 를 리스트 자료구조인것처럼 혼동한다.
- List(Interger)list = new ArrayList <>(); 처럼 리스트 자료구조와 같이 생각하도록 이름이 지어져 있다.
- 자바에서 ArrayList는 배열을 Collection 프레임워크 List 인터페이스에 맞춰 사용할 수 있게 만들어 둔것이다.
- 거기에 추가로 배열처럼 크기를 설정하지 않고 사용할 수 있으며 크기가 가변적이라는 추가 장단점이 있다.(메모리 효율 하락 : 단점 , 배열이지만 크기 가변적 사용 : 장점)
ArrayList
- 기본 동작 원리 및 CRUD 에 따른 효울성은 배열과 동일하다.
- 자바 자체 초보인 사람들은 리스트를 처음 사용 할 경우 ArrayList와 LinkedList 둘중 아무거나 쓰고나서 앞으로 계속 쓴다.
- LinkedList와 ArrayList의 CRUD 효율성은 다르기에 맞춰서 쓰지않으면 비효율적인 코드가 된다.
- 자바에서 ArrayList는 배열을 쓸 경우 효율적으로 동작할 로직을 수행하려하는데 배열의 크기를 모르고 배열로 구현하기 귀찮을 경우 사용하는 것이다.
- 배열로 해도 미리 넉넉하게 만들거나 다 찰 경우 미리 2배정도 늘려서 새로 만들면 ArrayList와 동일하게 사용 가능하다.
자바에서 ArrayList가 구현되는 내부코드
다음과 같이 Default Capacity(기본 배열 크기) 를 설정해둔것이 확인 가능하다.
맨 처음 크기 1개에서 시작하면 크기를 계속해서 늘려야하니 10개 정도로 잡아둔것이다.

다음과 같이 생성시에 원하는 기본크기 설정도 가능하며 정확히 어느정도 크기인지는 몰라도 감으로 맞춰 쓰면된다.

다음은 용량이 가득찬 경우 배열을 새로 할당받아 전부 복사하는 부분
변수 n 에 대해 n>>1은 모두 비트를 오른쪽으로 한칸 옮긴것이며 n/2를 뜻한다.
(n<<1은 같은 의미로 n*2를 뜻한다)
자바에서 기본적으로 배열의 크기를 1.5배씩 늘리며 ArrayList를 구현한것이 확인 가능하다.(n+n/2=1.5n)

자바에서 LinkedList와 ArrayList를 혼동하여 비효율적으로 사용하면 안된다.
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class Main {
private static void proc(List<Integer> list) {
long start = System.currentTimeMillis();
int sum = 0;
for (int i = 0; i < list.size(); i++)
sum += list.get(i);
System.out.println(sum);
System.out.println((System.currentTimeMillis() - start) / 1000f + " sec");
}
public static void main(String[] args) throws Exception {
// LinkedList
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 100000; i++)
list.add(i);
proc(list);
// ArrayList
list = new ArrayList<>();
for (int i = 0; i < 100000; i++)
list.add(i);
proc(list);
}
}Copy
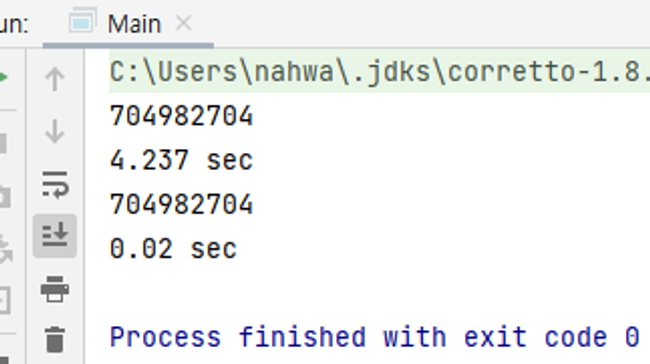
시간차이를 보기위해 임의의 위치 데이터를 읽어오는 경우를 표현한것.
Vector는 위에 설명한 자바의 ArrayList를 뜻한다
일반적 List는 LinkedList를 뜻한다.
배열을 위처럼 미리 크기를 정하지 않고 가득차면 몇배씩 늘리는 식으로 사용할 수 있게해둔 자료구조가 Vector라 한다.
자바의 Vector 자료구조
- 자바는 실제 Vector라는 자료구조가 존재한다.
- 자바에서 Vector와 ArrayList 차이점은 없다.하지만 ArrayList가 더 우수하니 사용하는것을 추천한다.
차이점으로는 Vector는 한 번에 하나의 Thread에서만 사용 할 수 있고 ArrayList는 여러 Thread에서 사용 할 수있다. Thread 여러개인 프로그램에서 서로 공유는 하되 락 걸어둔 것 처럼 사용할 경우가 아니라면 자바에서 Vector 쓸 일은 딱히 없다.
리스트라고 하면 LinkedList를 뜻한다.
메모리에서 손해를 보면 (trade-off)배열이 가득 차면 미리 1.5~2배 크기의 새로운 배열을 만드는 식으로 배열도 미리 크기를 설정하지 않고 가변크기처럼 사용 할 수 있으며 효율성은 배열과 동일하다.
이것을 Vector라고 하며 자바에서는 추가로 ArrayList라 한다.
Queue, Stack (큐, 스택+덱)
큐, 스택, 덱은 배열, 리스트와 함께 선형 자료구조에 속하는 자료구조들이다.
큐, 스택, 덱의 모든 기능은 리스트(이하 '리스트'라는 단어는 모두 Linked List를 뜻함)만 사용해서 시간복잡도 마저 동일하게 동작할 수 있다.
스택, 큐, 덱은 리스트에 포함되는 자료구조이며 별개의 자료구조로 정의되어 사용되며 일종의 컨셉, 규칙에 해당된다.

큐(Queue)
FIFO(First in First out: 선입선출) 의 특징을 가지고 있는 자료구조이다. (먼저 들어간 데이터가 먼저 나온다)

그림으로 위와 같이 좌우가 뚫려있는 파이프와 같이 표현되어 좌측으로 넣고 우측으로 뺀다.(한쪽 발향으로 넣고, 다른쪽으로 뺀다)
- 넣는 순서 : 노랑-> 보라->파랑
- 빼는 순서 : 노랑->보라->파랑
중간자료 확인 or 데이터 수정 방법
- enqueue로 방금 넣은 데이터를 다시 확인 할수 없다.
큐의 컨셉은 이러한 방법들을 전부 못하는 것이며 단순히 한쪽에서 넣고 빼고만 할 수 있게 제한해둔것이다.
함수
- enqueue() 자바는 add() : 한쪽 방향으로 데이터를 넣는다.
- dequeue() 자바는 poll() : 다른 쪽 방향으로 데이터를 뺀다.
- peek() : dequeue로 빠질 데이터를 큐에서 제거하진 않으며 데이터만 확인한다.
- inEmpty() : 큐가 비었는지 확인
- size() : 큐에 들어 있는 데이터 갯수
dequeue는 덱(deque)과 다르다.
deque는 double-ended queue, de-(접두어)+queue
import java.util.LinkedList;
public class MyQueue<T> {
LinkedList<T> list;
public MyQueue() {
list = new LinkedList<>();
}
public void enqueue(T data) {
list.addFirst(data);
}
public T dequeue() {
return list.pollLast();
}
public T peek() {
return list.peekLast();
}
public boolean isEmpty() {
return list.isEmpty();
}
public int size() {
return list.size();
}
}
언어별 Queue
- 자바는 Queue<Integer> q = new LinkedList<>(); 와 같이 선언해서 사용할 수 있다.
- 파이썬은 따로 큐를 제공하지 않고 배열도 없다.(리스트는 LinkedList가 아니다)
- C++은 STL에 만들어져있다.
- C는 LinkedList부터 기본적으로 제공되지않아 직접 짜야한다.
파이썬에서 List는 일반적으로 Vector(ArrayList)의 형식으로 동작하기에 dequeue에서 시간 복잡도가 너무 높아 비효율적이고 파이썬은 큐도 이후 설명할 deque(덱)를 사용해야한다.
Queue는 현업에서 대표적으로 스케쥴링에 쓰인다. 먼저 들어온 작업을 먼저 처리하도록 하는것.
스택 (Stack)
스택은 LiFO(Last in First out : 후입 선출) 의 특징을 가지는 자료구조이다. 나중에 들어간 데이터가 먼저 나온다.
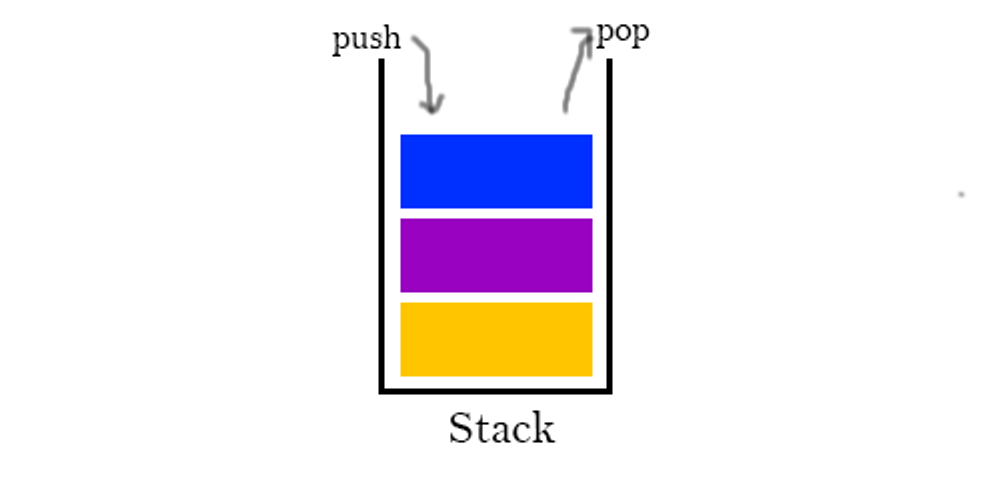
- 위와 같이 상자에 뚜껑을 열고 사이즈에 맞는 책을 차곡차곡 쌓는다라고 생각하면 된다.
- 마지막에 넣은 책이 가장 위에 있으니 먼저 꺼내야 아래책을 확인할 수 있다.
큐와 마찬가지로 중간 데이터를 볼 수 없고 수정 할 수 없다는게 스택의 컨셉
추가로 스택에서 가장 위에 있는 데이터는 top이라고 불린다.
함수
모든 함수의 시간 복잡도는 O(1)
- push() : 스택에 데이터를 넣는다.
- pop() : 스택에서 데이터를 뺀다.
- peek() : 스택에서 데이터를 빼지 않고 맨위에 있는 데이터만 확인한다.
- isEmpty()
- size()
import java.util.LinkedList;
public class MyStack<T> {
LinkedList<T> list;
public MyStack() {
list = new LinkedList<>();
}
public void push(T data) {
list.addFirst(data);
}
public T pop() {
return list.pollFirst();
}
public T peek() {
return list.peekFirst();
}
public boolean isEmpty() {
return list.isEmpty();
}
public int size() {
return list.size();
}
}
- 자바의 경우 Stack<Integer> stk = new Stack<>(); 와 같이 선언하여 사용가능
- 파이썬의 경우 일반적은 List를 사용해야한다. (stack -[])
- C++은 STL에 있다
- C는 직접 짜야한다.
C로 짜본 Stack : https://github.com/NaHwaSa/C_LanguagePractice/tree/main/stack%20(data%20structure)
C_LanguagePractice/stack (data structure) at main · nahwasa/C_LanguagePractice
C language practice :). C언어로 짜본 자료구조들. Contribute to nahwasa/C_LanguagePractice development by creating an account on GitHub.
github.com
Stack은 현업에서 Ctrl + Z로 현재 작업중인걸 되돌리는 기능으로 예시를 할 수 있다.
작업을 하나씩 진행하고 (push), Ctrl + Z를 할 때 마다 가장 마지막 작업한게 하나씩 취소 되어야 한다.(pop)
덱 (Deque = Double - ended Queue)
Dobule - ended Queue라는 의미, 양 쪽으로 넣고 뺼 수 있는 큐이다.
- 양쪽으로 넣고 뺄 수 있는 스택으로도 사용 or 한쪽은 스택 한쪽은 큐로 사용해도 된다.(더 유연한 큐이다.)
- 리스트와 다르게 중간의 데이터를 건드릴 수 없으며 양끝단만 건드릴 수 있다.
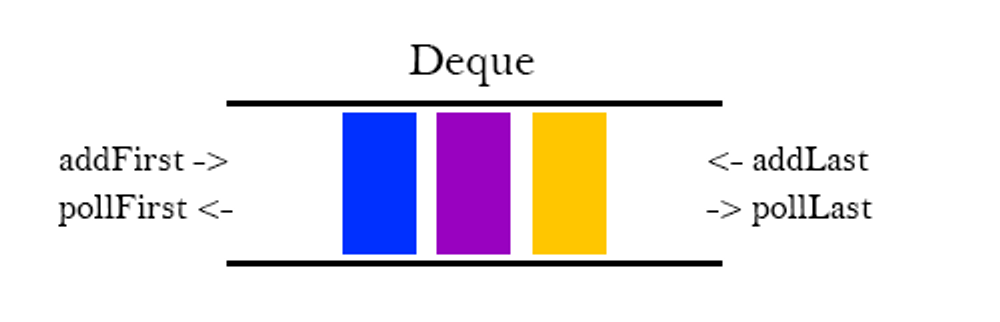
함수
모든 함수의 시간 복잡도는 O(1)
- addFirst() : 덱의 한쪽에 데이터 추가
- pollFirst() : 덱의 한쪽에서 데이터 빼기
- peekFirst() : 덱의 한쪽에서 데이터를 빼지않고 확인만 하기
- addLast() : 덱의 다른쪽에 데이터 추가
- pollLast() : 덱의 다른쪽에서 데이터 빼기
- peekLast() : 덱의 다른쪽에서 데이터를 빼진않고 확인만 하기
- inEmpty()
- size()
import java.util.LinkedList;
public class MyDeque<T> {
LinkedList<T> list;
public MyDeque() {
list = new LinkedList<>();
}
public void addFirst(T data) { list.addFirst(data); }
public T pollFirst() { return list.pollFirst(); }
public T peekFirst() { return list.peekFirst(); }
public void addLast(T data) { list.addLast(data); }
public T pollLast() { return list.pollLast(); }
public T peekLast() { return list.peekLast(); }
public boolean isEmpty() { return list.isEmpty(); }
public int size() { return list.size(); }
}
- 자바의 경우 Deque<Integer> dq = new LinkedList<>(); 와 같이 선언해서 사용가능하다.
- 파이썬은 from collections import deque 처럼 import 해서 사용이 가능하다
- C는 전부 직접 짜야한다.
스택, 큐의 한계를 덱으로 해결할 수 있다.
- 일반적으로 메모리 제한이 있기에 Ctrl + Z에는 횟수 제한이 있다.
- 스택은 추가/삭제만 가능하기에 설정해둔 갯수를 넘어가도 최근에 한 작업만 제거할 수 있다.
- 덱을 사용한다면 addFirst와 pollFirst로 스택처럼 사용하다가 size()를 확인 후 일정수치가 넘어갈 때 pollLast로 빼는 방법을 사용하여 갯수를 제한 할수 있다.
Hash Table (맵)
해시테이블(맵)은 키와 값의 쌍을 저장하는 자료구조이다.
해시테이블은 데이터가 많아지면 성능이 저하 될 수 있다.
Key : Value로 저장하는 데이터 구조
키를 통하여 바로 데이터를 받아올 수 있기에 속도가 획기적으로 빨라진다
해쉬 : 임의 값을 고정 길이로 변환하는것
해쉬 테이블 : 키 값의 연산에 의해서 직접 접근이 가능한 데이터 구조이다
해쉬 함수 : 키에 대해 산술 연산을 이용하여 데이터 위치를 찾을 수 있는 함수
해쉬 값/ 해쉬 주소 : 키를 해싱 함수로 연산하여 해쉬 값을 알아내고 이를 기반으로 해쉬 테이블에서 해당 키에 대한 데이터 위치를 일관성 있게 찾을 수 있다.
슬롯 : 한 개의 데이터를 저장 할 수 있는 공간
저장할 데이터에 대해 키를 추출 할 수 있는 별도 함수도 존재할 수 있다.

해시(Hash)
데이터를 효율적으로 관리하기 위해 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는것.
Lee -> 해싱함수 -> 5
Kim -> 해싱함수 -> 3
Park -> 해싱함수 -> 2
...
Chun -> 해싱함수 -> 5 // Lee와 해싱값 충돌
collision현상
데이터가 많아질 경우 다른 데이터가 같은 해시 값으로 충돌이 일어나는 현상
collision 현상이 발생해도 해시테이블을 사용하는 이유
- 적은자원으로 많은 데이터를 효율적으로 관리하기 위해
- 하드디스크나 클라우드에 존재하는 무한한 데이터들을 유한한 갯수의 해시값으로 매핑하면 작은 메모리로도 프로세스 관리가 가능해진다.
- 언제나 동일한 해시값 리턴, index를 알면 빠른 데이터 검색이 가능하다.
- 해시테이블의 시간복잡도 O(1) - 이진탐색트리는 O(lonN)
collision(충돌) 문제 해결 방법
- 체이닝 : 연결리스트로 노드를 계속 추가해나가는 방식(제한 없이 계속 연결이 가능하지만 메모리 문제가 있다)
- OPen Addressing : 해시 함수로 얻은 주소가 아닌 다른주소에 데이터를 저장 할 수 있도록 허용한다(해당 키 값에 저장되어있으면 다음주소에 저장한다)
- 선형 탐사 : 정해진 고정 폭으로 옮겨 해시값의 중복을 피한다.
- 제곱 탐사 : 정해진 고정 폭을 제곱수로 옮겨 해시값의 중복을 피한다.
Set(셋)
Set은 집합이라는 의미를 가진다.
array나 List 처럼 연결 자료구조(coollection)이지만 set은 순서라는 개념이 존재하지 않는다.
Set의 특징
- 데이터를 비순차적(unordered)으로 저장할 수 있는 순열 자료구조 (collection).
- 집합의 개념과 같다고 생각하면 된다 (집합 역시 {1, 9, 6,4}처럼 중복과 순서가 없다.
- 삽입(insertion) 순서대로 저장되지 않는다. 즉 특정한 순서를 기대할 수 없는 자료구조이다.
- 수정이 가능하다.(mutable)
- 동일한 값을 여러번 삽입이 불가능하다. (동일한 값이 여러번 삽입되면 하나의 값만 저장)
- Fast Lookup이 필요할 경우 주로 쓰인다
- Set이라는 인터페이스를 통하여 자바에서는 3가지의 Set이 있다. 일반적으로 HashSet, TreeSet, LinkedHashSet 순으로 빠르다.
- Hash 알고리즘을 이용한 HashSet
- 이진 탐색 트리를 사용하여 오름차순 정렬까지 해주는 TreeSet
- Set에 순서를 부여해주는 LinkedHashSet
Set의 구조
Array와 다르게 Set은 요소들을 순차적으로 저장하지 않는다
Set에서 요소들이 저장될 경우
- 저장할 요소의 값 hash값을 구한다.
- 해쉬값에 해당하는 공간(budket)에 값을 저장한다.
이렇게 set은 저장하고자 하는 값의 해쉬값에 해당하는 budket에 값을 저장하기에 순서가없다. 순서가 없어서 indexing도 없다.
그리고 해쉬값 기반의 bucket에 저장하기에 중복된 값을 저장 할 수 없다.
해쉬값을 기반으로 저장하기에 look up이 굉장히 빠르다
- Look up : 특정 값을 포함하고 있는지를 확인 하는 것.
- O(1) : Set의 총 길이와 상관없이 단순히 해쉬값 계산 후에 해당 bucket을 확인하면 된다.
HashSet
- 내부적으로 HashMap을 사용하여 값을 저장한다.
- 값의 중복을 허용하지 않는다.
- 값이 저장된 순서를 보장하지 않는다.
- null을 허용한다.
Set은 순서보장이 필요없고 중복은 없어야하는 이벤트 응모자 목록 과 같은 자료를 저장할 경우 사용할 수 있다.
해쉬값 기반이기에 조회속도가 빠른 장점을 사용해 실시간 처리에도 사용할 수 있다.
'Computer Science' 카테고리의 다른 글
| 스파르타 코딩클럽(부트캠프) 10장 HTTP/HTTPS (1) | 2024.03.28 |
|---|---|
| 스파르타 코딩클럽(부트캠프) 9장 OSI 7계층 (0) | 2024.03.27 |
| 스파르타 코딩클럽(부트캠프) 7장 자료의 저장과 표현 (5) | 2024.03.25 |
| 스파르타 코딩클럽(부트캠프) 6장 DBMS(데이터베이스 관리 시스템)의 기능과 종류 (2) | 2024.03.22 |
| 스파르타 코딩클럽(부트캠프) 5장 DB(데이터베이스) 구조와 유형 (0) | 2024.03.21 |



