
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #OSI #ISO #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- aws #아키텍트 #과정 #vpc #인프라 구축 #aurora #database #rds #rdbs #load #balancer #web #page #haproxy
- 공간복잡도 #공간자원 #캐시메모리 #SRAM #DRAM #시간복잡도
- aws #아키텍트 #과정 #vpc #인프라 구축 #rds #replica #복제본 #aurora #database #고가용성
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- aws #아키텍트 #과정 #vpc #인프라 구축 #php #alb #application #load #balancer #security #group #igw #ec2 #vpc #virtual #private #cloud
- aws #아키텍트 #과정 #vpc #인프라 구축 #s3 #bucket #객체 #스토리지 #isci #이미지 #업로드
- 프로세스 #CPU #시공유 #커널
- aws #아키텍트 #과정 #vpc #인프라 구축 #haproxy #round robin #process #high ability #auto scailling #app server #launch template
- aws #아키텍트 #과정 #vpc #인프라 구축 #ec2 #instance #launch #template #생성 #ami #amazone #machine #image
- aws #아키텍트 #과정 #vpc #인프라 구축 #auto scailling #lauch template #ec2 instace #private #subnet
- aws #아키텍트 #과정 #vpc #인프라 구축 #amazon sns #server #less #architecture
- 썸네일 #이미지
- aws #아키텍트 #과정 #vpc #인프라 구축 #sqs #trigger #python3.9 #패키지 #
- aws #아키텍트 #과정 #vpc #인프라 구축 #second nat #gateway #routing table #route53 #고가용성 #private subnet #
- 업로드 #lambda #함수 #모바일 이미지 #썸네일 이미지
- aws #아키텍트 #과정 #vpc #인프라 구축 #rds #endpoint #cloudwatch #monitoring
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #웹개발
- aws #아키텍트 #과정 #vpc #인프라 구축 #sqs #message #queue #sns구독
- 쓰레드 #쓰레드풀 #프로세스
- aws #아키텍트 #과정 #vpc #인프라 구축 #alb #load balancer #t.g #target #group #haproxy #high ability #db #replica #region
- aws #아키텍트 #과정 #vpc #인프라 구축
- 비트 #바이트 #이진수
- aws #아키텍트 #과정 #vpc #인프라 구축 #s3 #bucket #객체 스토리지 #objects storage #events #upload #알림
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스
- aws #아키텍트 #과정 #vpc #인프라 구축 #haproxy #고가용성 #테스트 #alb #application #load balancer #application
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #딥러닝 #AI #서버 #자동화 #SQL #기본문법 #데이터베이스 #DBMS #Oracle #MongoDB #아키텍쳐 #DB
- aws #아키텍트 #과정 #vpc #인프라 구축 #db #장애조치 #reand only #replica #events
- aws #아키텍트 #과정 #vpc #인프라 구축 #t.g #target group #alb #application #load #balancer #web #server
- 스파르타코딩클럽 #부트캠프 #IT #백엔드 #머신러닝 #AI #서버 #자동화 #SQL #KDT #기본문법 #데이터베이스 #Computer #Science #CPU #메모리
- Today
- Total
요리사에서 개발자
스파르타 코딩클럽(부트캠프) 12장 시간 자원과 시간 복잡도 본문
시간복잡도 : 프로그램의 수행시간 분석 결과 - 얼마나 빠르게 실행되는가
공간복잡도 : 프로그램의 메모리 사용량에 대한 분석 결과 - 얼마나 많은 자원이 요구되는가
시간자원
CPU시간자원이란
- 컴퓨터는 한정된 CPU를 여러 프로세스가 나누어서 사용한다.
- 이것을 효율적으로 나누어 사용하기 위해 CPU 스케쥴러를 통해 시간자원을 관리한다.
이 부분은 대부분 OS에서 관리해주는 부분이기에 우리가 다룰일은 많이 없지만 CS적으로 굉장히 중요하다.

CPU관리 (CPU 스케쥴링)
- 통상 CPU가 컴퓨터 한대에 하나가 장착되므로 여러 프로세스들이 CPU를 효율적으로 나누어 사용할 수 있도록 관리되어야한다.
- CPU를 가장 효율적으로 사용하면서도 특정 프로세스가 불이익을 당하지 않도록 하는것.
메모리 시간자원이란
메모리 CPU의 메모리와 주 메모리를 의미한다.
- 프로그램은 컴퓨터의 주 메모리 공간에 로드되어 CPU를 통해 연산 하기 때문에 연산하는 동안 사용하는 메모리 점유가능한 시간이 바로 프로그램의 시간자원이다.
프로그램을 개발할 때 가장 중요하게 고려해야하는게 시간자원으로 알고리즘시험도 이 시간자원을 줄이기 위한 시험이다.
- 프로그램의 시간자원은 기본적으로 메모리상에 데이터를 조회/연산은 수행하는 동작을 1개의 연산단위로 둔다.
- 기본 연산의 실행 횟수로 수행시간을 평가하는 이유는 수행시간이 실행환경에 따라 다르게 측정되기 때문이다.
- 데이터 입출력 - copy, move 등
- 산술 연산 - add, multiplay 등
- 제어 연산 - if, while 등
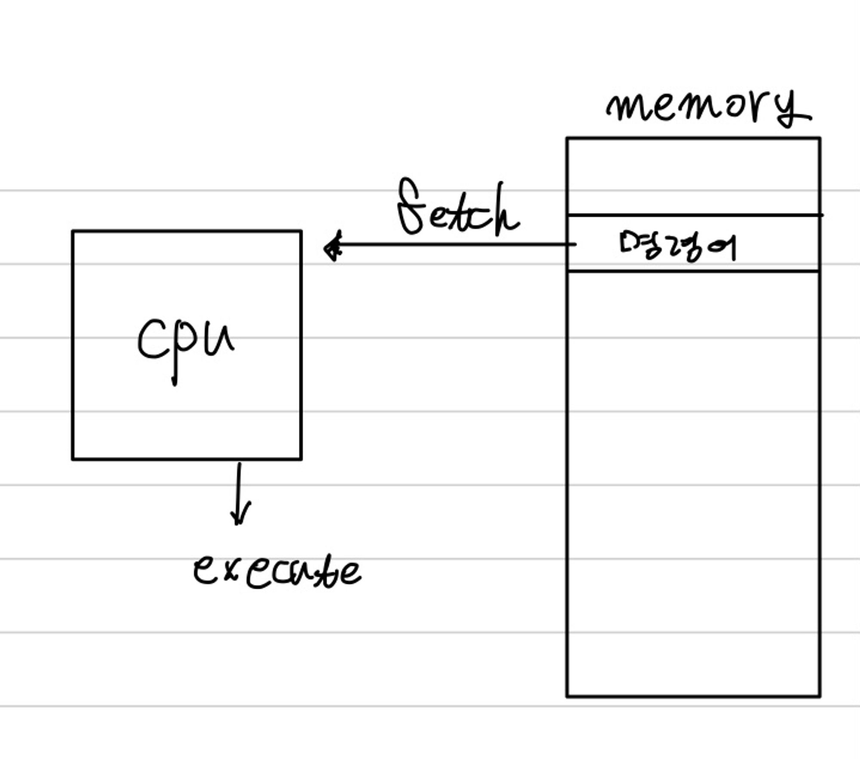
메모리 시간자원은 주 메모리에 로드 되어있는 프로그램이 CPU를 사용하면서 입력의 크기와 문제를 해결하는데 허용하는 소모시간을 의미한다.
- 알고리즘 문제에 시간제한이 1초 - > 알고리즘 해결 프로그램은 1초의 메모리 시간자원이 주워진것.
- 서버 프로그램의 요구사항에 입력후 2초 이내에 응답 -> 서버 프로그램은 2초의 메모리 시간자원이 주워진것.
네트워크 시간자원이란
컴퓨터는 다른 컴퓨터와 통신하기위해 네트워크망을 사용하며 네트워크를 구성하는 OSI 7계층 안에 여러 시간자원이 존재한다.
특히 서버 프로그램을 만들어 운영할 때 여러가지 Timeout설정을 하게 되며 이를 통해 시간자원을 관리한다.
이 외 네트워크의 여러 계층은 기본적 Timeout이 설정되어 있는 곳도 있다.
타임아웃(Time out) 이란
네트워크에서 타임아웃(Time out)은 장치나 프로그램이 연결을 중단하기 전까지의 응답시간을 의미한다.
- 두 장치간에 네트워크 통신 시 커넥션(연결)이 발생하면 데이터를 주고 받는다.
- 이때 어떠한 이유로 데이터가 손실되거나 전달이 지연되는 등의 이유로 대기가 발생할 수 있다.
- 대기가 무한정 이어지는 것을 막기 위해 정해진 시간이 지나면 타임아웃에 의해서 연결이 해제된다.
타임아웃 종류
- 커넥션 타임아웃
- 세션 타임아웃
- 서버 타임아웃
- DNS 타임아웃
타임아웃이 필요한 이유
지속적인 연결시도 방지
- 장치와 장치간 연결이 될 때 문제가 있어서 응답 대기 시간이 길어질 수 있다.
- 이때 타임아웃에 의해 연결 해제 및 오류를 알려줌으로 문제 상황을 인지시킬 수 있다.
Ex)
사용자가 웹사이트에 접속-> 웹서버가 다운되어 정상 접속이 되지않는다-> 타임아웃이 없다면 웹브라우저는 계속해서 서버에 연결을 시도( 또 다른 문제가 이어질 수있다)-> 타임아웃이 된다-> 브라우저는 지정된 시간이 지나면 연결을 중단한다-> 오류메시지 출력
리소스 고갈 방지
- 하나의 프로그램은 여러 개의 커넥션을 생성한다.
- 어떤 이유로 응답 대기 시간이 길어지는 커넥션이 쌓인다.
- 사용 가능한 리소스가 모두 소진되고 프로그램 전체 장애가 밣생할 수 있다.
- 타임아웃은 이를 방지해준다.
Ex)
클라이언트가 서버에 요청을 보냄-> 네트워크 문제로 서버는 여러 클라이언트의 요청에 제대로 응답이 불가능-> 대기하는 커넥션 발생 -> 리소스 고갈
타임 아웃을 통해 때가 되면 또 다른 응답을 받을 준비를 할 수 있다.
보안 강화
- 불 필요하게 세션이 오래 연결되어 있는 상태를 방지한다.
- 로그인 세션 타임아웃이 대표적인 예
- 은행 앱에 접속하고나서 일정 시간 동안 이용하지 않으면 알아서 세션이 종료되고 로그아웃된다.(웹사이트도 마찬가지)
시간 복잡도
시간 복잡도 계산법
빅오 표기법이란
시간복잡도 함수에서 상대적으로 불필요한 연산을 제거하여 알고리즘의 분석을 조금 더 간편하게 할 목적으로 시간복잡도를 표기하는 방법이다.
- Big-O(빅 - 오) -> 상한 점근
- Big- Ω(빅 - 오메가) -> 하한 접근
- Big- θ(빅 - 세타) -> 그 둘의 평균
이 세가지 표기법은 시간 복잡도를 각각 최악, 최선, 중간(평균)의 경우에 대한 방법이다.
불필요한 연산이란 상수값을 제외하고 큰 흐름인 추세만 표기하여 계산하는 방법이다.
Ex) O(n), O(nlogn)

O(1) < O(log n) < O(n) < O(n^2) <(n^3)<O(2^n)
O(1)이란
일정한 복잡도(constant complexity)라고 하며, 입력값이 증가하더라도 시간이 늘어나지 않는다.
입력값의 크기와 관계없이 즉시 출력값을 얻어낼 수 있다는 의미
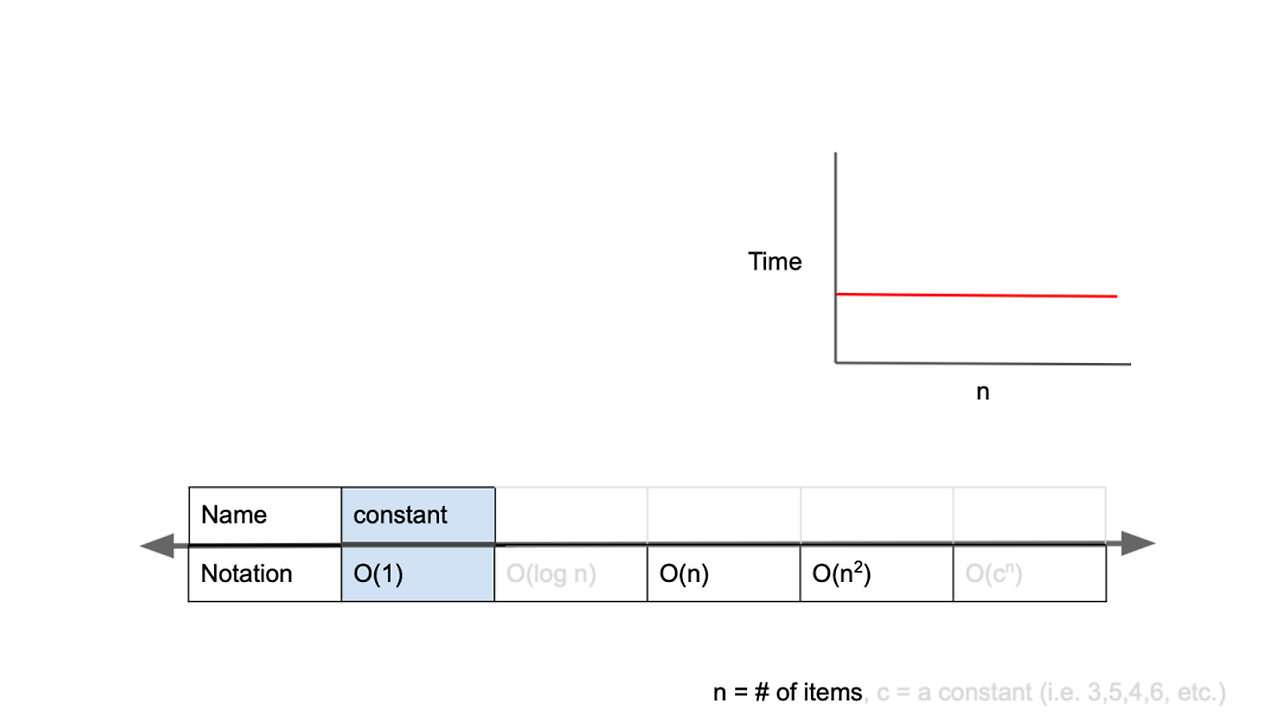
O(1)의 시간 복잡도를 가진 알고리즘
function 0_1_algorithm(arr, index) {
return arr[index];
}
let arr = [1, 2, 3, ,4, 5];
let index = 1;
let result = 0_1_algorith(arr, inex)
console.log(result) ; //2
- 이 알고리즘에선 입력값의 크기가 아무리 커져도 즉시 출력값을 얻어낼 수 있다.
- 예를 들어 arr의 길이가 100만이라도 해당 index에 접근하여 값을 반환할 수 있다.
O(n)이란
선형 복잡도(linear complexity)라고 부르며 입력값이 증가함에 따라 시간 또한 같은 비율로 증가하는 것을 의미한다.
Ex) 입력값이 1일 때 1초, 입력값을 100배로 증가하면 1초의 100배인 100초가 걸리는 알고리즘을 구현했다.
이 알고리즘은 O(n)의 시간복잡도를 가진다
O(n)의 시간 복잡도를 가진 알고리즘
function 0_n_algorithm(n) {
for (let i = 0; i < n; i++) {
// do something for 1 scond
}
}
function another_0_n_algorithm(n) {
for (let i = 0; i < 2n; i++) {
// do something for 1 second
}
}
- 0_n_algorithm 함수에선 입력값(n)이 1 증가할 때마다 코드의 실행 시간이 1초씩 증가한다.
- 입력값이 증가함에 따라 같은 비율로 걸리는 시간이 늘어나고 있다.
- another_0_n_algorithm은 입력값이 1 증가할때마다 코드의 실행 시간이 2초씩 증가한다.
- 이 알고리즘은 O(2n)이라고 표현하며 Big-O 표기법으로는 O(n)이라 한다.
입력값이 커지면 커질수록 계수(n 앞에 있는 수)의 의미(영향력)가 점점 퇴색되기에 같은 비율로 증가한다면 2배가 아닌 5배, 10배로 증가하더라도 O(n)으로 표기한다.
O(log n)이란
로그 복잡도 는 logarithmic complexity이라고도 부르며 Big-O 표기법중 O(1) 다음으로 빠른 시간 복잡도를 가진다.
O(log n)은 밑이 2인 log2n을 일방적으로 나타낸다.
void Logarithmic (n) {
i - 1; //1
while(1<n) {
printf(1) ;
i - i * 2; // 2의 거듭제곱으로 커집니다.
}
}
while (i<n) 만 보면 n번 반복할 것 같지만 i=ix2 로 인해 숫자는 1 -> 2-> 4-> 8-> 16.. 인 2의 거듭제곱으로 커지기 때문에 위 while 문은 log2 n 만큼 반복된다.
1 + log2 n + 1+log2n = 3log2 n+2 = > O(log n)
void logarithmic (n) {
i = n; //n
while(i>1) {
printf(i);
i - i /2; // 2의 거듭제곱으로 작아진다.
}
}
// 나눗셈도 마찬가지!
log n 의 대표 탐색 알고리즘은 이진탐색이다.
- 자료구조에 BST(Binary Search Tree) 이진탐색이 있다.
- BST 에선 원하는 값을 탐색할 때 노드를 이동할 때마다 경우의 수가 절반으로 줄어든다.
- 이해하기 쉬운 게임으로 비유해 보자면 up&down을 예로 들 수 있습니다.
- 1~100 중 하나의 숫자를 플레이어 1이 고른다. (30을 골랐다고 가정한다.)
- 50(가운데) 숫자를 제시하면 50보다 작으므로 down을 외친다.
- 1~50 중의 하나의 숫자이므로 또 다시 경우의 수를 절반으로 줄이기 위해 25를 제시한다.
- 25보다 크므로 up를 외친다.
- 경우의 수를 계속 절반으로 줄여나가며 정답을 찾는다.
- 매번 숫자를 제시할 때마다 경우의 수가 절반이 줄어들기 때문에 최악의 경우에도 7번이면 원하는 숫자를 찾아낼 수 있게 됩니다.
- BST의 값 탐색 또한 이외같은 로직으로 O(log n)의 시간 복잡도를 가진 알고리즘(탐색기법)
O(n^2)이란
2차 복잡도 quadratic complexity 라고 부르며 입력값이 증가함에 따라 시간이 n의 제곱수의 비율로 증가하는 것을 의미한다
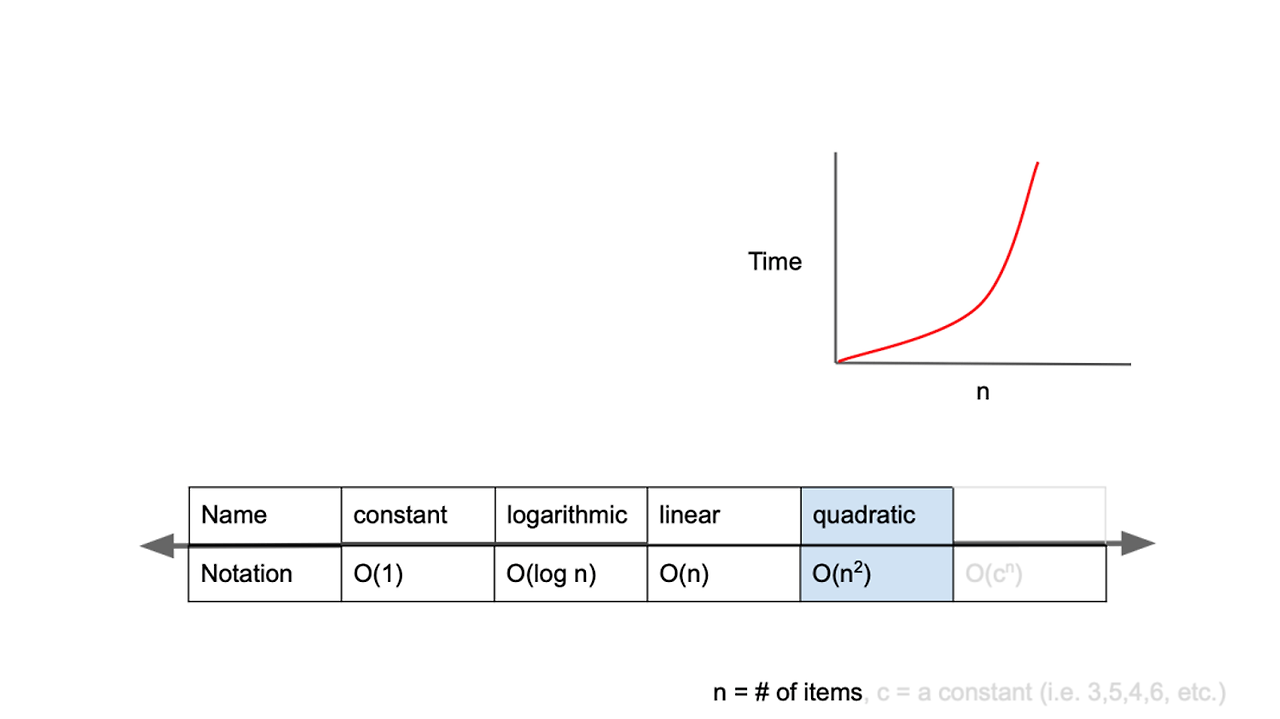
- 입력값이 1일 경우 1초가 걸리 알고리즘에 5라는 값을 주었더니 25초가 걸리게 된다면 알고리즘의 시간 복잡도는 O(n^2)라고 표현한다.
O(n^2)의 시간 복잡도를 가진 알고리즘
function O_quadratic_algorithm(n) {
for(let i = 0; i < n; i++) {
for (let j = 0; j < n; j++) {
//do something for 1 second
}
}
}
function another_O_quadratic _algorithm(n) {
for (let i = 0; i < n; i++) {
for(let j = 0; j < n; j++) {
for(let k = 0; k < n; k++) {
// do something for 1 second)
}
}
}
}
- 2n , 5n을 모두 O(n)이라고 표현하는 것처럼 n3와 n5도 모두 O(n2)로 표기한다.
- n이 커지면 커질수록 지수가 주는 영향력이 점점 퇴색되기에 이렇게 표기한다.
O(2^n)
기하급수적 복잡도exponential complexity 라고 부르며 Big-O 표기법 중 가장 느린 시간 복잡도를 가진다.
구현한 알고리즘의 시간 복잡도가 O(2^n)이라면 다른 접근 방식을 고민하는것이 좋다.
O(2^n)의 시간 복잡도를 가진 알고리즘
function fibonacci(n) {
if (n<=1) {
return 1;
}
return fibonacci(n - 1) + fibonacci( n -2 ) ;
}
- 재귀로 구현하는 피보나치 수열은 O(2^n)의 시간 복잡도를 가진 대표적인 알고리즘이다.
- 브라우저 개발자 창에서 n을 40으로 두어도 수초가 걸리는 것을 확인할 수 있고 n이 100 이상이면 평생 결과를 반환받지 못할 수도 있다.
자료구조 별 시간 복잡도
Array
- 데이터의 순서(index)가 있다.
- 데이터의 수가 고정일 경우 주로 사용한다.

ArrayList
- 배열과 달리 전체 크기(사이즈)가 가변적이나 사이즈를 늘릴 때 오버헤드가 발생한다(= Dynamic Array)

Queue
- 배열의 비해 메모리를 효율적으로 사용할 수 있다.

Deque(Double Ended Queue)
- 양쪽 끝에서 데이터의 삽입/삭제가 가능한 큐
- Deque 로 Queue와 Stack을 구현할 수 있다.

Stack
- 스택을 활용한 유명한 문제로는 펠린드 룸 문제가 있다.
- 함수(메소드)의 호출은 내부적으로 스택 자료구조를 이용하여 동작한다.

알고리즘 별 시간 복잡도
- 각각의 알고리즘을 수행하는데 연산(산술, 대입, 비교, 이동) 들이 몇 번 이루어지는지를 숫자로 표기한다.
- 동일한 알고리즘 입력되는 데이터에 따라 실행시간이 다르며 최선, 평균, 최악의 경우로 나누어질 수 있다.
정렬 알고리즘 별 시간 복잡도
삽입정령 (Insertion Sort)
장점
- 최선의 경우 O(N)이라는 엄청나게 빠른 효율성을 가지고 있다.
- 성능이 좋아서 다른 정렬 알고리즘의 일부로 사용될 만큼 좋은 정렬법이다.
단점
- 최악의 경우 O(N^2)이라는 시간 복잡도를 갖게된다.
- 데이터의 상태 및 데이터의 크기에 따라 성능의 편차가 굉장히 심한 정렬법이다.
선택정렬 (Selection Sort)
장점
- 선택정렬 또한 버블정렬과 마찬가지로 구현이 쉬운편에 속하는 정렬법이다.
- 정렬을 위한 비교 횟수는 많지만 실제로 교환하는 횟수는 적기때문에 많은 교환이 일어나야 하는 자료상태에서 효율적으로 사용될 수 있다.
- 버블정렬과 비교하였을 때 똑같이O(N^2)이라는 시간복잡도를 갖지만 시간이 버블정렬에 비해 조금더 빠른 정렬 방식이다.
단점
- 선택정렬 또한 항상 O(N^2)이라는 시간 복잡도를 갖기에 시간이 오래걸리는 정렬방식이다.
버블정렬 (Bubble Sort)
장점
- 구현이 쉽다.
- Bubble 정렬은 인접한 값만 계속해서 비교하면 되는 방식으로 굉장히 구현이 쉬운편이다.
- 코드 자체가 직관적이다.
단점
- 굉장히 비효율적이다.
- 최악이든 최선이든 O(N^2)이라는 시간복잡도를 갖기에 알고리즘에서 효율적인 정렬방법으로 사용되지않는다.
퀵 정렬(Quick Sort)
장점
- 기준값에 의한 분할을 통해 구현하는 정렬법
- 분할 과정에서 logN 이라는 시간이 걸리게되고 전체적으로 보게되면 NlogN으로 실행시간이 준수한 편이다.
단점
- 기준값(Pivot)에 따라서 시간복잡도가 크게 달라진다.
- Pivot이 적당하게 이상적인 값을 선택했다면 NlogN의 시간복잡도를 갖지만 최악으로 Pivot을 선택할 경우 O(N^2)이라는 시간복잡도를 갖게된다.
병합정렬 (Merge Sort)
장점
- 퀵소팅과 비슷하게 원본 배열을 반씩 분할해가며 정렬하는 정렬법
- 분할하는 과정에서 logN만큼의 시간이 걸린다.
- 최종적으로 보게되면 NlogN이 된다.
- 퀵소팅과 달리 Pivot을 설정하거나 그런 과정 없이 무조건 절반으로만 분할하기에 Pivot에 따라 성능이 안좋아지거나 하는 경우가 없다.
- 항상 O(NlogN)이라는 시간복잡도를 갖게된다.
- 정렬법들 중 매우 준수하다.
단점
- 장점만 보면 퀵보다는 무조건 병합 정렬을 사용하는 것이 좋을 수 있으나 추가적인 메모리가 필요한 큰단점이 있다.
- 병합정렬은 임시배열에 원본맵을 계속해서 옮겨주며 정렬하는 방법이다.
- 추가 메모리 할당이 없을 경우 데이터가 최악이라면 병합정렬이지만 추가 메모리 할당이 되지않아 퀵을 써야한다.

시간 복잡도 별 알고리즘
- N :문제에 주어진 반복 변수
- 백준 : 아래 표와 비슷하게 나온다
- 프로그래머스 : N을 조금 여유롭게(작게)주는 타입(대기업에서는 잘 안나온다) -중구난방이다.
알고리즘에서 log는 밑이 10인 log(10)가 아니라 밑이 2인 log(2)이다.
log(10)100,000 = 5, log(2)100,000 = 16

시간자원의 한계
CPU 시간자원의 한계
1코어란
스케쥴링을 통하여 많은 수의 프로세스(프로그램을)를 동시 실행시킬 수 있는 프로세서
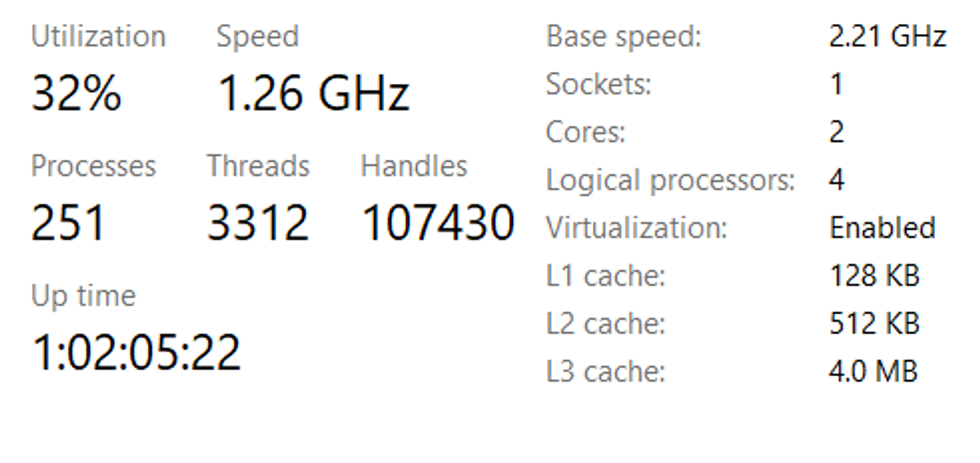
- Logical Processor 는 4개
- Process는 251개가 현재 돌아가고있다.
- Thread 갯수는 3312개.
- 한정된 개수의 Logical Processor 위에 많은 수의 Proces와 Thread가 동작할 수 있는 이유는 운영체제가 CPU를 가상화시켜주기 때문이다.
- 한정된 자원인 CPU를 무한개의 CPU가 존재하는 것처럼 변환하여 동시에 많은 프로그램을 실행시키는 것이다.
프로세서가 한개일 경우
- 하나의 프로세서에서 MultiThreaded Process가 실행될 때 프로세서는 시분할을 통하여 CPU가 여러개인 듯한 추상화를 제공한다.
- 스레드 간 Context-Switching을 하며 번갈아 실행함으로 동시에 실행되고 있는 것처럼 보이는 것이는 것을 스케쥴링이라한다.
스케쥴링의 단위
프로세스 실행은 "CPU실행 <-> 입/출력 대기"의 반복을 의미한다.

CPU Burst
- 프로세스의 사용중 연속적으로 CPU를 사용하는 구간을 의미한다.
- 실제 CPU를 사용하는 스케쥴링의 단위
I/O Burst
- 프로세스의 실행 중 I/O 작업이 끝날때까지 Block 되는 구간을 의미한다.
스케쥴링 알고리즘 평가기준
- CPU이용률 : 전체 시스템 시간중 CPU가 작업을 처리하는 시간의 비율
- 처리량 : CPU가 단위 시간당 처리하는 프로세스의 갯수
- 총 처리 시간 : 프로세스가 시작해서 끝날 때 까지 걸리는 시간
- 대기 시간 : 프로세스가 준비완료 큐에서 대기하는 시간의 총 합
- 응답 시간: 대화식 시스템에서 요청 후 첫 응답이 오기까지 걸린 시간
스케쥴링 알고리즘 종류
선입선출(FCFS : First com, First Served)기법
- 먼저 도착한 프로세스를 먼저 처리한다.
- 먼저 CPU를 얻은 프로세스가 원하는 작업을 완료할 때 까지 다픈 프로세스들은 CPU 사용이 불가능하다.
긴 수행시간의 프로세스로 인한 짧은 수행시간을 가진 프로세스들 마저 순서를 기다려야 하는 단점 이 있다.
라운드 로빈(Round Robin) 기법

- CPU를 한 번 할당받아서 사용할 수 있는 시간을 일정하게 고정된 시간으로 제한한다.
- 일반적으로 1회 할당시간은 밀리초 단위를 사용한다
- 선입선출기법의 단점을 해결가능하다.
다수의 사용자가 동시에 접속하더라도 각자 1초 이하의 응답시간을 보장받을 수 있다.
우선순위(Priority) 기법

- 대기중인 프로세스들에 우선순위를 부여하여 높은 우선순위의 프로세스에게 CPU를 먼저 할당한다.
- 외면당하는 프로세스가 생기지 않도록하며 기다린 시간이 늘어날수록 우선순위를 점차 높여주는 방법도 적용이 가능하다.
메모리 시간 자원의 한계
1초 : 일반적인 컴퓨터가 약 1~5억번의 메모리 접근을 하며 연산 가능한 시간이다.
- 프로그램의 시간자원은 기본적으로 메모리상에 데이터를 조회/연산을 수행하는 동작을 1개의 연산단위로 두고있다.
- 이렇게 기본 연산 실행횟수로 수행시간을 평가하는 이유는 수행시간이 실행환경에 따라 다르게 측정되기 때문이다.
- 시간 복잡도는 입력의 크기와 문제를 해결하는데 걸리는 시간의 상관관계를 의미한다.
- 시간복잡도를 구하는 이유는 시간초과 여부를 확인하기 위해서 이다.
기본연산
- 데이터 입출력 - copy, move 등
- 산술 연산 - add, multiply 등
- 제어 연산 - if, while 등
그래프를 보았을 때 N이 커짐에 따라 시간복잡도의의 차이가 수행시간에 아주 큰 영향을 주는 것을 알 수 있다.

- O(1) 상수
- O(logN) 로그시간
- O(N) 선형시간
- O(N log N) 이나 O(N^2) 처럼 N의 곱셈형식으로 표현되는건 다항시간
- O(2^N) 지수시간
- O(N!) 팩토리얼 시간
- N이 25이하가 아니라면 지수시간은 시간초과를 통과하기가 어렵다.
- N이 11이하가 아니라면 팩토리얼도 시간초과를 통과하기 어렵다.
1초 안에 연산을 할수 있는 N의 크기에 따른 시간복잡도

- 알고리즘을 코드로 구현하기 전에 미리 시간복잡도를 알아내어 코드로 구현할 가치가 있는 코드인지를 확인하는게 중요하다.
- 일반적인 코딩테스트 에서 특별한 명시가 없다면
- 제한 시간 : 약 1~5초 이며 그 이상은 시간초과(Time Limit Exceeded)
- 제한 시간은 언어마다 다르고 연산양(시간 복잡도)이 중요하다.
따라서 시간 복잡도 계산 결과 연산양이 1억 이상이면 거의 100%시간 초과라고 보면된다.
일반적인 컴퓨터의 성능
- 1초(sec) - > 약 100,000,000(1억)회 연산 가능
- 0.1초(sec)-> 약 10,000,000(1천만)회 연산 가능하다.
log(10) vs log(2)
컴퓨터 공학에서는 로그는 대부분 밑이 2이기에 시간복잡도 계산시 log 1000은 10, log2000은 11, log1000000은 20 이다
네트워크 시간자원의 한계란
대표적으로 Connection Time out, Socket Timeout, Read Time out 3가지의 타임오류가 있다.
일반적으로 대부분의 네트워크 프로그램에서 사용하는 TCP는 연결지향(Connection-Oriented) 프로토콜로 커넥션을 수립(establish) 한 후 그 커넥션을 통하여 클라이언트와 서버가 데이터를 송수신한다.

연결지향 네트워크 프로그램 작동방식(Ex TCP) <-> UDP
- 클라이언트가 서버의 IP와 포트를 이용하여 서버에 커넥션을 요청한다.
- 서버가 클라이언트 커넥션 요청에 수락 응답을 전송한다.
- 커넥션이 수립되며 클라이언트가 서버로 요청데이터를 전송한다.
- 서버는 클라이언트로부터 받은 요청데이터에 대해 처리한 후 응답을 클라이언트로 전송한다.
- 웹(WEB) : 웹브라우저는 클라이언트가 되고 웹서버는 서버가된다.
- DB : 애플리케이션은 클라이언트가 되고 클라이언트로부터 SQL을 받아 처리하는 DB는 서버가 된다.
- 카카오톡 : 카카오톡 프로그램이 클라이언트가 되고 카카오 데이터센터 서버에 있는 카카오 서버 프로그램이 서버가된다.
Connection Timeout
Connection Timeout은 Connection을 구성하는데 소요되는 시간의 임계치를 의미
- 웹 브라우저는 3 Way Handshake 방식으로 서버와 연결을 맺는다
- 위 작업이 수행되는 총 걸린 시간을 Connection Time 이라 한다.
- Connection Time을 무한으로 설정할 수 없어 일정시간을 지정한다.
- 그시간을 초과하면 Connection Timeout이 발생한다.
Socket Timeout
- 서버는 클라이언트와 연결을 맺은 후 여러 개의 패킷으로 데이터를 클라이언트에 전송한다.
- 각 패킷이 전송될 때 시간 Gap이 생긴다. 이를 Socket Timeout 이라 한다.
- Socket Timeout은 개별 패킷에 대한 시간의 임계치이다.
- Socket Timeout의 Target은 전체 응답시간이 아닌 개별 응답시간이다.
Socket Timeout의 Target은 전체 응답 시간이 아닌 개별 응답 시간이다.
Socket Timeout : 1초
응답 패킷 : 3개
각 패킷 도착 시간 : 0.9초
총 응답 시간 : 2.7초
위와 같은 상황은 개별 패킷들이 1초안에 도착하였기에 Socket Timeout이 발생하지 않는다.
Read Timeout
클라이언트가 서버에 접속은 성공하였으나 클라이언트의 요청에 서버는 오랫동안 응답을 못하여 클라이언트가 연결을 해제하는것이 Read Timeout이다.
- Read Timeout은 Socket Timeout과 유사하다.
- 읽을 수 있는 데이터가 있기 전 시간초과가 만료되면 자바프로그램의 경우 java.net.SocketTimeoutException이 발생한다.
- 클라이언트의 요청이 서버에서 수행을 늦게 성공함으로써 싱크가 맞지않아 문제가 발생할 수 있다.
네트워크 오류 정리
정리하자면 Connection Timeout과 Socket Timeout 설정은 모두 필요하다
위 두가지 Timeout을 설정하지 않으면 URL 접속시 무한대기가 발생할 수 있다.
네트워크 오류 종류
커넥션 풀(시간자원 한계)
- 클라이언트가 서버에 요청을 보낼 때 커넥션을 맺느라 소요되는 시간과 리소스를 절약하기 위해 커넥션풀을 사용한다.
- 1,2 단계를 통해 만들어진 커넥션 객체를 풀에 넣어둔 요청을 전송해야될 필요가 있을 때 바로 꺼내서 응답을 받은 후 커넥션을 풀에 다시 반납한다.
네트워크 프로그램의 오류
- 보통 네트워크 프로그램이 문제가 없으나 아주 가끔씩 발생한다.
- 네트워크 프로그램에서 발생하는 오류의 종류와 원인을 알아두면 어떤부분을 점검해야할지 알 수 있다.
Connection Refused
- 클라이언트가 IP와 포트를 이용하여 커넥션을 요청했는데 이 요청이 들어간 서버에 해당 포트번호를 Listen하고 있는 서버가 없다는 뜻.
Connection Timeout(시간자원 한계)
- 커넥션 요청을 보낸다.
- 어딘가에 문제가 생겨 커넥션 수락이 오지않는다.
- 프로그램이 대기상태에서 영원히 멈춰있을수 없기에 Connection Timeout은 정해진 시간까지 커넥션 수락이 오지않아 발생한다.
- 클라이언트가 1번으로 서버에 커넥션을 요청할 때 는 커넥션 타임아웃을 설정해 둔다.
Read Timeout(시간자원 한계)
- 커넥션이 수립된 후 클라이언트가 서버로 요청데이터를 전송한다.
- 이때 서버로부터 응답을 받을 때 까지 얼마나 오랫동안 기다릴지 설정하는것이 Read Timeout이다.
- 클라이언트가 요청데이터를 보낸 후 이 시간동안 서버로부터 응답데이터를 못 받으면 오류가 발생한다.
Too many Open Files.
- 파일을 오픈 할 때 뿐만 아니라 네트워크 클라이언트 프로그램이 소켓을 오픈 할경우 File Descriptor를 사용한다.
- 네트워크 소켓이 허용된 갯수보다 많이 열려고 시도할 경우 위와 같은 오류가 발생한다.
- 현재 오픈되 잇는 파일과 소켓을 보고싶으면 Isof나 pfiles 명령을 이용하여 확인할 수 있다.
'Computer Science' 카테고리의 다른 글
| 스파르타 코딩클럽(부트캠프) 알고리즘 특강정리 (1) | 2024.04.26 |
|---|---|
| 스파르타 코딩클럽(부트캠프) 11장 공간자원과 공간 복잡도 (6) | 2024.03.29 |
| 스파르타 코딩클럽(부트캠프) 10장 HTTP/HTTPS (1) | 2024.03.28 |
| 스파르타 코딩클럽(부트캠프) 9장 OSI 7계층 (0) | 2024.03.27 |
| 스파르타 코딩클럽(부트캠프) 8장 자료구조의 동작과 활용 (3) | 2024.03.26 |



